Статті
-
Як створити .NET-обфускатор - Частина I
Це буде коротка серія про те, як створювати .NET-обфускатори. Техніки певною мірою схожі для інших мов, але я виберу ту, яку знаю найкраще.
Щоб рухатися далі, я рекомендую трохи знати C#, ECMA-335 - Partition II: Metadata Definition and Semantics, і хоча б чути про .NET-бібліотеку для модифікації метаданих - dnlib.
Також варто знати про стекові віртуальні машини та IL opcodes. Якщо хочете краще зрозуміти семантику кожного opcode, прочитайте ECMA-335.
-
How to build .NET obfuscator - Part III
This is continuation of series about writing obfuscators. You can read first article here, and second one here
Second part ends with showing basic condition generation and dead code injection. Let’s learn how to improve generation of the noise expression today.
-
Аналіз змін в кодовій бази Bun після перепису із Zig на Rust
Мене трішки довели хайпом навколо перепису Bun на Rust. Я вирішив подивитися що це означає на практиці.
Я не буду робити ніяких висновків, лише зроблю акценти які мені здається важливими, та дам числа для діскусії.
Коміт де відбулися зміни це https://github.com/oven-sh/bun/commit/23427dbc12fdcff30c23a96a3d6a66d62fdc091d . Для початку я швидко вирішив подивитися що було із тестами. В Bun я бачу лише інтеграційні тести в репозіторі. Ці інтеграційні тести мають наступні характеристики.
18 610 тестів існує. Мабуть справжне число на декілька тисяч більше, бо я рахував грепом, а не в рантаймі. 1546 файлів із тестовими групами (тобто де в принципі описані тести) 3582 тестових групп (describe).ще вони запускають тести від https://github.com/elysiajs/elysia. Це
1 581 тестів додатково. 130 файлів із тестовими групами (тобто де в принципі описані тести) 151 тестових групп (describe).Сумарно
20 191існує тестів.630 690рядків Zig було (на 100 менше до переписування). Стало899 067рядків RustЩо дає щільність покриття коду тестами.
- в Zig було
1 тест на 33 рядківкоду - в Rust стало
1 тест на 44 рядківкоду
Для порівняння в NodeJS
8 015 всього тестів існує. 1 026 файлів із тестовими групами (тобто де в принципі описані тести) 3 267 файлів які самі є тести.138 759рядків JS108 782рядків C++
Сумарно
247 541рядків коду.Щільність покритя коду
1 тест на 30 рядків.Також треба враховувати що Bun це рантайм. При тестуванні надійності рантайму мало прогнати тести, ще важливо щоб рантайм коректно вів себе на всіх кінцевих продуктах. Це взагалі не проблема зазвичай у прикладних продуктах. Для них важливіше мати лише інтеграційні тести. Скоріш за усе важливо скільки рядків коду виконує рантайм при запуску конкретних тестів кінцевих продуктів. Найближчий приклад із корпоративного світу на мою думку це розробникі фреймворків та платформ команди із дуже строгою системою обратної сумісності щодо своїх продуктів.
Також на мою думку важливо при зміні реалізації мати набагато більше тестів ніж для звичайної еволюції продуктів, бо при еволюції ти менше міняєш, і менше шансів мати велику кількість незареестрованих нових поведінок яка ніж неприємні кінцевому кліенті ніж при більш великим кускам змін.
Чи цього достатньо для контролю 900 тисяч нових рядків чи ні в цьому продукті я думаю вирішувати вам. Будьте зважені коли намагаєтесь досягти аналогічних результатів у себе на проекті.
- в Zig було
-
Analysis of changes in the Bun codebase after the rewrite from Zig to Rust
I was a bit carried away by the hype around rewriting Bun in Rust. I decided to see what that means in practice.
I won’t draw any conclusions; I’ll only highlight points that seem important to me and give numbers for discussion.
The commit where the changes happened is https://github.com/oven-sh/bun/commit/23427dbc12fdcff30c23a96a3d6a66d62fdc091d. To start, I quickly checked what happened with the tests. In the Bun repository I only see integration tests. These integration tests have the following characteristics.
-
Generating a .NET Emulator
Hello LLM-users. I want to create an IL/.NET VM emulator, for example for malware sandboxing. I decided to do it this way: use fuzzing as a general quality control process for execution.
I see the following semi-automated emulator building processes:
- Progress monitoring process
- Implementation process
- Implementation validation process
- Bug fixing process
- Manual recovery process
The overall process can be visualized as follows:
flowchart TD classDef llmTask fill:orange,stroke:#333,stroke-width:4px,color:#333; classDef llmGeneratedScript fill:lightGreen,stroke:#333,stroke-width:4px,color:black; classDef humanCode fill:green,stroke:#333,stroke-width:4px,color:white; START([Start]) FINISH([End]) %% General flow START --> Progress Progress -->|Implement new instruction| Impl Progress -->|No unimplemented instructions| FINISH Impl -->|Success| Validation Impl -->|Failed to implement| RecoveryProcess Validation -->|Errors found| BugFix BugFix -->|Success| Validation BugFix -->|Failed to implement| RecoveryProcess Validation -->|Success| Progress Validation -->|Failed to implement| RecoveryProcess -
Генеруя .NET емулятор
ЛЛМ панове. Хочу зробити емулятор IL / .NET VM, наприклад для сендбоксінга малварі. Вирішим ось так зробити, взяти фазінг як процес загального контролю над якістю виконання.
Я бачу наступні процеси напівавтоматичного побудови емулятора
- Процес контролю прогресу виконання
- Процес реалізації
- Процес контролю реалізації
- Процес коригування багу
- Процес ручного відновлення
Узагальнено процесс можна побачити таким чином.
flowchart TD classDef llmTask fill:orange,stroke:#333,stroke-width:4px,color:#333; classDef llmGeneratedScript fill:lightGreen,stroke:#333,stroke-width:4px,color:black; classDef humanCode fill:green,stroke:#333,stroke-width:4px,color:white; START([Початок]) FINISH([Кінець]) %% Загальний flow START --> Progress Progress -->|Реалізувати нову інструкцію| Impl Progress -->|Немає нереалізованих інструкцій| FINISH Impl -->|Успішно| Validation Impl -->|Не вийшло реалізувати| RecoveryProcess Validation -->|Помилки знайдено| BugFix BugFix -->|Успішно| Validation BugFix -->|Не вийшло реалізувати| RecoveryProcess Validation -->|Успішно| Progress Validation -->|Не вийшло реалізувати| RecoveryProcess -
Comment construire un obfuscateur .NET - Partie II
Ceci est la continuation de la série sur l’écriture d’obfuscateurs. Vous pouvez lire le premier article ici
Nous avons terminé avec le remplacement de chaînes et l’obfuscation primitive du runtime. Il est maintenant temps de compliquer les choses un peu. Jusqu’à présent, nous avons écrit des techniques d’obfuscation relativement simples, qui sont assez triviales à défaire. Dans cet article, je vais expliquer comment transformer le flux de contrôle de manière à rendre la vie un peu plus difficile.
Commençons par rendre le flux de contrôle plus difficile à suivre.
-
How to build .NET obfuscator - Part II
This is continuation of series about writing obfuscators. You can read first article here
We finished with string replacement and primitive obfuscation runtime. Now it’s time to spice things up a bit. Before that we write relatively simple obfuscation techniques, which is quite trivial to undo. In this article I would explain how to transform control flow in such way that make your life a bit harder.
Let’s start make control flow harder to follow.
-
Comment construire un obfuscateur .NET - Partie I
Ce sera une courte série sur la façon de construire des obfuscateurs .NET. Les techniques sont quelque peu similaires pour d’autres langages, mais je choisirai celui que je connais le mieux.
Pour suivre, je vous recommande de connaître un peu de C#, ECMA-335 - Partition II : Définition des métadonnées et sémantique, et au moins d’avoir entendu parler de la bibliothèque .NET pour la modification des métadonnées - dnlib
Vous devriez également connaître les machines virtuelles à pile, et les opcodes IL. Si vous souhaitez mieux comprendre la sémantique de chaque opcode, veuillez lire ECMA-335.
-
How to build .NET obfuscator - Part I
This would be short series on how to build .NET obfuscators. The techniques is somewhat similar for other languages, but I will choose that one which I know the best.
For the following along, I would recommend to know a bit of C#, ECMA-335 - Partition II: Metadata Definition and Semantics, and at least hear about .ENT library for metadata modification - dnlib
You also should know about stack virtual machines, and IL opcodes. If you want to know better semantics of each opcode, please read ECMA-335.
-
Китайський Open Source: Вичерпна історія
Це переклад дуже цікавої історії Chinese Open Source: A Definitive History — Kevin Xu, Interconnected яка точно багатьом не відома — китайськй відкритий код. Сама країна доволі закрита для іноземців і складно знати що там коїться якщо там не живеш, тому історії про те що відбувається, чи видбувалося в країні завжди цікаво. Маю надію що вам сподобається
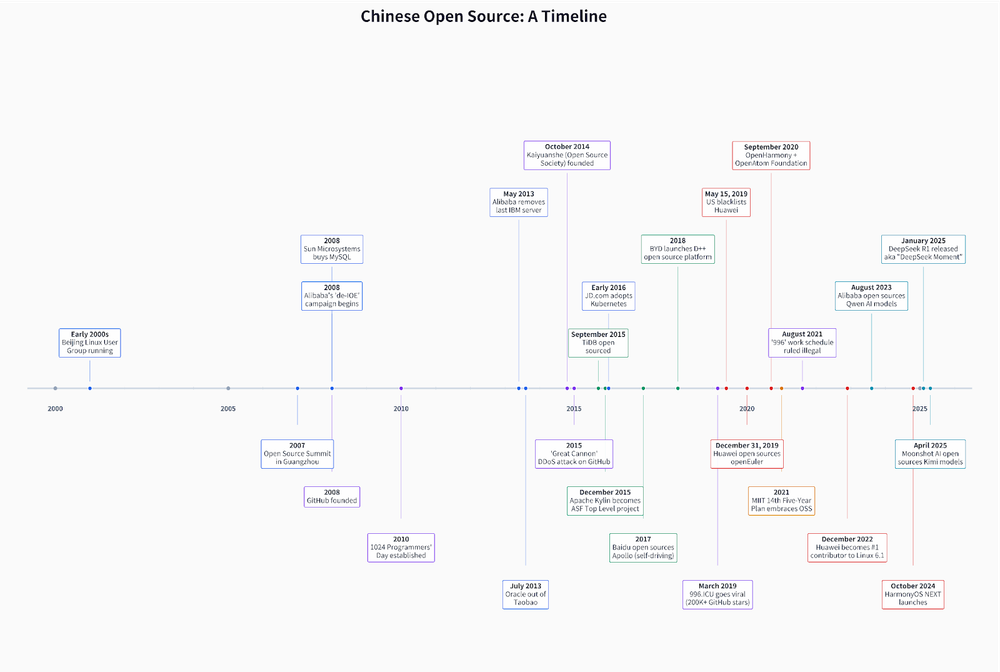
-
Що доводить доведення в Lean?
Трішки вільний, бо стиль автора дуже стислий, переклад статті (https://supaiku.com/what-does-a-lean-proof-prove) від spike.
Альтернативна назва: епістеміка довіри до Lean з точки зору практикуючого програміста.
Коротко:
- Исторія Lean є несуперечливою відносно ZFC
- Основна реалізація, схоже, опосередковано відповідає теорії.
- Реалізація переважно вільна від помилок судячи із практики.
- Помилки, які наразі були виявлені, не були фатальними і виправлені.
- Окрім головноії реалізації існує невелика, але зростаюча сім’я незалежних реалізацій, які підкріплюють модель довіри до Lean та доведень, написаних у ньому.
- Можливо, не варто довіряти твердженням про програмне забезпечення, написане на Lean.
-
Отчет по тестированию Oylan
Увидел я в одном чате ссылку на ЛЛМ систему казахстанского производства Oylan. Как я понимаю это исследовательский продукт, но не протестировать я не мог. Вот мои наблюдения.
-
Compiling Ada-
Recently Ada compiler from 1988 was appear on the Internet. That immidiately caught my attention, since I was always intrigued by Ada, since I can say my second programming language was Pascal. So this post would be about my journey towards compiling old Ada using modern compiler.
-
Bureaucratic view of SemVer
Semantic Versioning always rub me wrong way, as reckless policy. Why?
-
Bureaucratic analysis of Twilio Microservices journey
We have a political discussion in our Ukrainian software architecture chat, and it usually tires people, so I bring this article from 2018 to divert attention. It was one of the first articles I found on well-known sources of boredom for software developers, like Hacker News, Lobsters, etc. Surprisingly, it was not very interesting to our taste, and I actually had to read it. Who could have guesses that you should read articles. That led to a good discussion about why microservices were probably not the problem.
Bureaucratic perspective
Since I happen to see how government procurement works, and what can cause organizational problems afterwards, the article was full of hints that show other kinds of problems, completely unrelated to those discussed in the article. I just cannot unsee them. These things are obviously not hard truths. Take it with a grain of salt, and use your own judgment. But please discuss how exactly organizational decisions affect technical work. I think that’s a super important part of software architecture, which is not discussed often.
-
Create dnSpy extension
I do love reverse engineering, for some strange reasons that starts with reversing .NET Reflector and never ends to this day. I was at security minded meetup at Almaty and speak with one of the speaker about possibility for MCP for deobfuscation in de4dot, and he propose that dnSpyEx would be better workflow, and he did try create plugin for it, but essentially give up on it for some reasons. Since I’m more of software developer then security analyst, that should be no problem for me, so let’s try and document the process.
Creating project
For creation of plugin, we need create Class Library.
dotnet new classlibrary -o dnspypluginDnSpy comes in two flavours - .NET Framework one, and .NET one, so you need to choose what TFM you want to target. You should choose either
net48ornet8.0-windows. That largerly would depends on what version of dnSpy you download. I choose .NET, so I make sure that my project has<TargetFramework>net8.0-windows</TargetFramework>in the project file.The plugins rely on the contract with dnSpy which declared in the
dnSpy.Contracts.DnSpy.dll. You have to manually add reference to that file, since it’s not available on Nuget.<ItemGroup> <Reference Include="dnSpy.Contracts.DnSpy"> <HintPath>full-path-to\local\dnspy\dnSpy.Contracts.DnSpy.dll</HintPath> </Reference> </ItemGroup>Obviously you can vendor this DLL, and place it in
libfolder near your source code and check in. But that’s sounds sooooo 2010. Not gonna back to this time. Pick your poison though.Also discovery of the plugin files rely on convention,
dnSpylook for*.x.dllfiles in thebinfolder, so you should tweak you assembly name.Add one more customization
<AssemblyName>dnspyplugin.x</AssemblyName>to project file.Since you want UI for your plugin, at least for configuration, you want WPF. Enable it please -
<UseWpf>true</UseWpf>.Plugin wiring rely on the MEF, so please add
<PackageReference Include="System.ComponentModel.Composition" Version="8.0.0" />to list of your dependencies.Now place this code to Class1.cs file which comes from template. I prefer have it renamed to
TheExtension.csfor conventions.using System.Windows; namespace dnspyplugin; [ExportExtension] public sealed class TheExtension : IExtension { public void OnEvent(ExtensionEvent @event, object? obj) { } public ExtensionInfo ExtensionInfo => new() { ShortDescription = "Your test plugin", }; public IEnumerable<string> MergedResourceDictionaries { get; } = []; }That’s it. Now you can build your project. Now go to your dnSpy installation, and create
extensionsfolder. Placednspyplugin.x.dllin that folder, and startdnSpy. Then go toHelp -> About, you can see “Your test plugin” in the list of loaded extensions.That’s it for the initiation.
Create menu item
Let’s create some interesting, the whole menu item which will appear on assembly.
using System.Windows; using dnSpy.Contracts.Menus; namespace dnspyplugin; [ExportMenuItem( Header = "My Menu Header", Group = MenuConstants.GROUP_CTX_DOCUMENTS_TOKENS, Order = 11)] public sealed class MyMenuItem: MenuItemBase { public override void Execute(IMenuItemContext context) => MessageBox.Show("Hello, this is useless menu."); }That’s bare minimum for the menu. We specify class which inherited from
MenuItemBase, mark it withExportMenuItem, where we at least specify menu title usingHeaderproperty, group where menu will appear. In our caseMenuConstants.GROUP_CTX_DOCUMENTS_TOKENSis group menu items on the node in Assembly Viewer windows.If you want to have menu, for example in the main application menu, registration would be a bit different
[ExportMenuItem(OwnerGuid = MenuConstants.APP_MENU_HELP_GUID, Header = "My Menu Header", Group = MenuConstants.GROUP_APP_MENU_HELP_LINKS, Order = 11)] public sealed class MyAboutMenuItem: MenuItemBase { public override void Execute(IMenuItemContext context) => MessageBox.Show("Hello, this is useless menu."); }Notice
OwnerGuidwhich specify main menu item inside which menu item appears. I do not have clear guidance how to guess which menu group I want place from the start. Only guessing and a bit of experimenting I guess can help.Tool content
If you want to add some additional tool panel, you should wrote a bit more code. Firstly you will wrote tool content provider which will inform dnSpy about content panes. And then actual tool pane implementation. Let’s start from content provider
using dnSpy.Contracts.ToolWindows; using dnSpy.Contracts.ToolWindows.App; // ... [Export(typeof(IToolWindowContentProvider))] public class MyToolWindowContentProvider : IToolWindowContentProvider { public MyToolWindowContent DocumentTreeViewWindowContent => analyzerToolWindowContent ??= new MyToolWindowContent(); MyToolWindowContent? analyzerToolWindowContent; public IEnumerable<ToolWindowContentInfo> ContentInfos { get { yield return new ToolWindowContentInfo( MyToolWindowContent.THE_GUID, AppToolWindowLocation.DefaultHorizontal, AppToolWindowConstants.DEFAULT_CONTENT_ORDER_BOTTOM_ANALYZER, isDefault: false); } } public ToolWindowContent? GetOrCreate(Guid guid) => guid == MyToolWindowContent.THE_GUID ? DocumentTreeViewWindowContent : null; }That’s most simple implementation where we declare available content using
ToolWindowContentInfodescriptor. Just global Guid identifying the specific tool window withing dnSpy. Technically you may have multiple contents returned here, for example as additional documentations.Second part is providing UI content for the specific Guid. It’s implemented in the
GetOrCreatemethod. We just laziely create instance ofMyToolWindowContenthere. And now let’s look at how it is implemented.public sealed class MyToolWindowContent : ToolWindowContent { public static readonly Guid THE_GUID = new Guid("5827D693-A5DF-4D65-A1F8-ACF249508A96"); public override IInputElement? FocusedElement => null; public override FrameworkElement? ZoomElement => _content; public override Guid Guid => THE_GUID; public override string Title => "My tool window"; public override object? UIObject => _content; private FrameworkElement _content; public MyToolWindowContent() { _content = new Label() { Content = "My tool window content" }; } }Your responsibility is implement
FocusedElement,ZoomElement,Guid,TitleandUIObjectand that’s it. Most interesting here isUIObjectproperty which actually WPF content which would be displayed. I use label here, but you can use anything else.I understand that this is bare minimum, but from that point, you can create your own interesting dnSpy plugin!
-
Migrating .NET Framework application
Today I look at the chat, and seen person was excited that it convince manager to ditch VS 2015 in favor VS 2022 and have new modern .NET. Based on previous experience it think that it only should update version of .NET and maybe libraries and voilà it will be in the new and shiny world of .NET. Right from .NET 4.6.2 hell.
Let’s say that’s not true. I’m very cautious person, especially when updating legacy application and I think a lot of advices which suggest either rewrite or just update libraries and somehow deal with breakage, or go for one big bang update on the separate branch. That feeling make me sick. I cannot take that unnescessary risk, so I would try to suggest how one can safely, albeit slowly upgrade existing application.
Rewrite and YOLO upgrade maybe reasonably choice, but not usually when you on tight budget and lack of hands. If you feel that’s for your, please listen to my advices. You don’t have .NET super fast, but your will get to it safely on the cheap.
Preparations for journey
I think if you want safely update existing application it would be long journey. You should be prepared to walk slowly. So as first start which everybody can do is take following steps
- Firstly just migrate your Nuget packages from packages.config to PackageReference. That make things a bit easier to version control and still suppported by “old” projects style.
- Secondly I would recommend just upgrade existing projects to new MSBuild SDK style. That immmidiately make your project more easier to understand and you get ediiting support in the Visual Studio. You will love your projects.
- Now I recommmend update your
LangVersionto latest possible. You will have almost all latest C# features, while still being on .NET Framework runtime. I also love to use PolySharp from Sergio Pedri to make even more C# features available in .NET Framework.
That’s only preparation steps. You should make only one step at a time, and probably wait couple of releases, test runs until you confident that everything is settled and any bugs don’t get introduced. There always possibility to get small issues if you have lot of projects, so don’t rush. Second step also can make you couple surpises in your build scripts, or CI/CD infrastructure. Try to solve them, before you go forward. Take your time to understand why do you need change some MSbuild customizations.
One example with MSBuild things, is that maybe you cannot use
SolutionDirvariable. But you can always createDirectory.Build.propsfile where you add following<Project> <PropertyGroup> <RepoRoot>$(MSBuildThisFileDirectory)</RepoRoot> </PropertyGroup> </Project>Now you can use
RepoRootinstead ofSolutionDirand don’t rely on VS for building.Oops, forget to mention. Don’t upgrade MVC project, you should do something else with them instead. I will explain what exactly later.
Know your pain points
Before upgrading, you should learn where your pain points can be. I would say, common offenders would be EF 6 and ASP.NET MVC and System.Web. That’s parts which should be your primary concerns.
Right now, because you have modern infrastructure, you can start playing with building for multiple runtimes. For that you change in you project file
<TargetFramework>net462</TargetFramework>to
<TargetFramework>net462</TargetFramework> <!-- <TargetFrameworks>net462;net8.0</TargetFrameworks> -->Reason for commenting out building for multiple runtimes is becasue most likey your build would failed, and you don’t ready jet for switch to new runtime. You will comment first line, uncommment second one and try, look at build issues and think a lot.
But what can simplify and scope your work. If you don’t have already, abstract your entry point for MVC application in one WebApplication project, and all business logic, or code which don’t depends on System.Web, and System.Web.Mvc should go into separate project. That project would be easier to migrate to supporting multiple runtime. Maybe you already have your application split by layers, and that would be a big help. I think you will have at least 3 projects (or project groups) after migrations
- CoreLogic - WebLogic - MvcWebApplicationCoreLogicis project where you don’t have any dependency on System.Web/System.Web.Mvc and friends. That’s most easy to upgrade things.WebLogicis project where you will move code which depends on the System.Web and System.Web.Mvc, it would be controllers, different kind of Web helpers which usually present in your code. You probably don’t need to put some DI code here, let it liveMvcWebApplicationMvcWebApplicationis project where you keep your views, Global.asax, some OWIN code and initializations of whole system. That’s only part which should be rewritten and thrown away. Note: view would be copied over and modified, but that’s another storyWork diligently to move as much code as possible here. Maybe you need a bit of refactoring to have proper separations. Logic is following -
coreLogicis relatively easy to upgrade,WebLogicis moderately risky to upgrade andMvcWebApplicationis code which should be thrown away and written from scratch.EF upgrade
Now matter how you would like to have EF Core, don’t jump onto it, you will lose your multi target abilities and that make your like more complicated then needed. Update EF6 to latest possible version at this time. It would be at least 6.5.1 as of Aug 2025. It support at least .NET 6 and that’s enough to live in new world.
Almost ready to start
Make sure that you be able build in multitarget configuration your
CoreLogicproject first. That require guessing right upmost version of your dependencies. Work on one dependency at at time, because lot of time passed, Google forget about small nuances which should be used for migration, they are not part of active index, so you should thread you path carefully.Sometimes dependencies act irresponsibly and drop .NET Framework support without having transition period of supporting both .NET Framework and .NET Core. In that case probably you should try create conditional dependency
Before:
<ItemGroup> <PackageReference Include="ThirdParty" Version="2.0.0" /> </ItemGroup>After:
<ItemGroup> <PackageReference Include="ThirdParty" Version="2.0.0" Condition="$(TargetFramework)=='net462'" /> <PackageReference Include="ThirdParty" Version="3.0.0" Condition="$(TargetFramework)!='net462'" /> </ItemGroup>Use it only if you need. Don’t use that technique to move to latest third party version. It’s too risky. Please don’t. If you want wild right, go for big band rewrite and take responsibility for whole rewrite if you have guts to do that.
ASP.NET MVC upgrade
That’s most stupid part, but you probably have to do it. That’s one of rare cases where
#ifwould come handy.#if !NET462_OR_GREATER using Microsoft.AspNetCore.Mvc; #else using System.Web.Mvc; #endifThat would be almost enough to make code compile. You will still have issues with System.Web namespace, but I suggest hide then under some helper classes which you will massage with
#ifconstructs.If you have ASP.NET Indentity in some controllers, I have following snippets.
#if !NET48 using ApplicationSignInManager = Microsoft.AspNetCore.Identity.SignInManager<MyApp.ApplicationUser>; using SignInResult = Microsoft.AspNetCore.Identity.SignInResult; #else using SignInResult = Microsoft.AspNet.Identity.Owin.SignInStatus; #endifand during usage I have to resort to
#ifs again.var isAdmin = await this.applicationUserManager.IsInRoleAsync( #if !NET462_OR_GREATER user, #else user.Id, #endif "Administrator");for logout I have following code
#if !NET462_OR_GREATER await this.HttpContext.SignOutAsync(IdentityConstants.ApplicationScheme); #else this.signInManager.AuthenticationManager.SignOut(DefaultAuthenticationTypes.ApplicationCookie); await Task.CompletedTask; #endifalso
ApplicationUsermaybe a bit customizedusing System.Security.Claims; using System.Threading.Tasks; #if !NET462_OR_GREATER using Microsoft.AspNetCore.Identity; #else using Microsoft.AspNet.Identity; #endif /// <summary> /// Application user. /// </summary> public class ApplicationUser #if !NET462_OR_GREATER : IdentityUser<int> #else : IUser<int> #endif { /// <summary> /// Initializes a new instance of the <see cref="ApplicationUser"/> class. /// </summary> /// <param name="id">Id of the user to create.</param> public ApplicationUser(int id) { this.Id = id; } #if NET462_OR_GREATER /// <summary> /// Gets id of the user. /// </summary> public int Id { get; private set; } /// <summary> /// Gets or sets unique name for the user. /// </summary> public string UserName { get; set; } /// <summary> /// Gets or sets hash of the user password. /// </summary> public string PasswordHash { get; set; } /// <summary> /// Gets or sets email of the user. /// </summary> public string Email { get; set; } /// <summary> /// Generate claim identity from given user. Used by OWIN /// </summary> /// <param name="manager">User manager which use for generation of claims.</param> /// <returns>Task which return claims identity for current user.</returns> public async Task<ClaimsIdentity> GenerateUserIdentityAsync(UserManager<ApplicationUser, int> manager) { // Note the authenticationType must match the one defined in CookieAuthenticationOptions.AuthenticationType var userIdentity = await manager.CreateIdentityAsync(this, DefaultAuthenticationTypes.ApplicationCookie); // Add custom user claims here return userIdentity; } #endif }In general lot of ASP.NET Identity stuff should be
#ifaway as only for .NET 4.6.2 because it’s different from ASP.NET Core Identity. Not a lot of things to retrofit here. Anyway do try make it.Also if you use DI, and you probably should even in MVC application I also recommend create
IHttpContextAccessor.namespace Microsoft.AspNetCore.Http; #if NET462_OR_GREATER using System.Web; public interface IHttpContextAccessor { HttpContext? HttpContext { get; } } public class HttpContextAccessor: IHttpContextAccessor { public HttpContext? HttpContext => HttpContext.Current; } #endifI think you get gist of my idea what you should do with this application. Make it build with multi-targeting setup. You will have bugs here guaranteed, but at least you find lot of problematic places where your logic would be changed during migration, and all of that would be catched by compiler. So you can think about these places.
Don’t try to make it compile in multi-target way in one go, move slowly and careully. Firstly you need that you legacy application work flawlessly, that give you buy-in from management to continue moving this goal, since it’s slow.
Finishing touches
Now you should create new ASP.NET Core MVC application and put only initialization logic there, and copy
Viewsfolder from yourMvcWebApplicationapplication. It would immidiately start prodoce build errors, but all of them usually trivial and require you to useawaita lot.In case you have DI like AutoFac or other previously, keep using it in new application. Read about ConfigureContainer and UseServiceProviderFactory
If you have bundles in ASP.NET MVC, they are no more in ASP.NET Core MVC
@*@Styles.Render("~/bundles/jquery-ui/themes/base/css") @Styles.Render("~/bundles/bootstrap/css")*@Probably easier migration path would be to use libman.json
Migrate tests
After you migrate
CoreLogicproject, you should run multi-target tests for them. You definitely want to run tests over new configuration to sleep safely.You probably cannot make nice tests over this web part. You should start over with test over this thing. If you use Playwright previously you may try to run test over new ASP.NET Core application. At least you will guess how hard your migration would go.
The end!
Now you can run this application and start noticing issues and bugs. And here the hard work started. I cannot say what exactly you will experience, since it’s largely depends on the application. I know, that migration is never easy, but up to this point you shake your application good enough, so you will better understand how to move forwad. Also you did safe work. Remember that green field rewrite is for these with unlimited budgets and stamina. I’m really too old (def. not lazy) for that.
-
Мій досвід використання LLM як перекладача
Я вже доволі давно використовую LLM для перекладу статей, які мені здається цікавими, і які як мені здається корисні для комьюніті. Мій процес перекладу доволі простий.
- Я відкриваю матеріал для перекладу в одний вкладинці браузера.
- Відкриваю місце для я зберігаю переклад, це Markdown файли в VS Code.
- Після чого я беру невеликий блок тексту, параграф чи декілька параграф і відправляю це в ChatGPT. Хочу звернути увагу, що саме лістінгі із кодом та приклади шеллу, я не перекладав через ChatGPT, бо тексту для перекладу там завжди мало, і великий ризик помилку зробити. Коментарі перекладав через Google Translate.
- Далі я копіюю переклад із ChatGPT в вікно VS Code.
- І після цього намагаюся уважно прочитати весь текст, і підредагувати якщо мені щось неподобається. Це зазчивай, стилістика перекладу, додавання пропущеної розмітки, як мені здається кращім, зміна рівня вкладеності заголовків та відновлення ідентифікаторів та ключових слів які чудо-машина вирішила перекласти як звичайні слова.
- Якщо я бачу серйозну помилку чи галюцінацію від ЛЛМ, я йду до Google Translate і перекладаю текст, потім повертаюся до крока 5 (редагування чернетки) і закінчую на цьому.
- Далі я повторю кроки 3-5 поки не втомлюся чи, поки текст не закінчиться. Чим більше текст, тим більше шансів що мене переможе втома, бо уважно читати це мені важко. Мабуть як і робити будь що уважно.
- Після закінчення перекладу, я саджуся читати все. Знову я намагаюся це робити уважно, але інколи я дуже втомлююся, або я хочу підкласти цей переклад під існуючу діскусію, яка мене і зтрігерила на переклад.
- Потім після першої валідації, я публікую результат. Дивлюся, як воно виглядає, і потім вже розповідаю іншим про статтю, так чи інакше.
- Через тижні два, я намагаюся повернутися, і перечитати наново весь текст. знову таки уважно. Це поки найкрихкий процес, тому що інколи я забуваю, а інколи мені ліньки це робити, бо читачі поки нічого не казали, або терплять мене або я не такий вже і цікавий. Але я знаю що це для мене обов’язковий етап, бо коли я забуваю контекст, і приходжу як читач, мені набагато легше перевірити якість своєї праці, ніж робити це по гарячому.
Як можна бачити, ЛЛМ в цьому процесі відіграє лише 1 частину - первинного перекладу. Після цього, більша частина часу тепер займає, вичитування, та редагування дрібних помилок. Через це, я доволі толерантно відношуся до будь-яких помилок ЛЛМ, бо хоча вони мене дратують, але у практиці це не є великою проблемою, якщо ти не пуріст. А я вже майже не пуріст. Також варто зауважити, що я не бачу як я зможу прийнятно щось перекласти якщо буду ваншотити переклад, і автоматизувати процесс так, щоб ШІ переклав мені весь тескт. Зараз я маю як мінімум два етапи перевірки якості перекладу, і цього недостатньо для мене. Шансів що я буду дуже уважно перечитувати все із нуля додатково, якщо я буду робити це дуже мало ймовірно. Умовно кажучи, автоматизація із ШІ прибере важливий етап 5, де я перечитую параграфи на те що вони складно читаються і немає термінологічних помилок.
Промпти
Ось приклади запитів які я робив для початку сесії перекладу.
Відтепер я хочу, щоб ти генерувала перекладала на українську, доки я не скажу стоп. Результат перекладу повинен бути надо у Markdown. Не роби висновки та сумарізацію.Я хотів би, щоб ти генерувала переклад на українську вічно, 1 промпт за раз. Всі результати видавай в форматі Markdown. Не роби висновки та сумарізацію. Не перефразуй речення. Не обмежуйся одним реченнямГенеруй переклад на українську, доки я не скажу "заверши переклад". Результат перекладу повинен бути надо у Markdown. Не роби висновки та сумарізацію.Останній запит. я тількі вирішив його попробувати, і дуже мало переклав із ним, щоб зрозуміти чи будуть якісь проблеми.
Генеруй переклад на українську, доки я не скажу "заверши переклад". Результат перекладу обов'язково повинен бути бути відформатован в Markdown. Не роби висновки та сумарізацію. Не додавай код. Переклада не відходячи від орігінального тексту. Перекладай як професійний перекладач.Помилки
Тепер коли я описав свій робочий процесс, я розповім про деякі цікаві помилки від ЛЛМ, які я побачив.
Помилка №1.
ЛЛМ інколи любить перекладати всередині маркдаун розмітки для коду. Це було прикольно, що таку саму помилку робили люді коли речення короткі. Умовно качужи
intro tacticправильно потрібно перекласти якТактика intro, бо intro це умовно кажучи ключове слово (технічно це не так) а tactic це звичайний термін Lean4 - тактика. Ця помилка просто типова помилка при автоматичному перекладі, нічого особливого, але і ЛЛМ тут не панацея, бо люди так само помилялися. Я коли відправив на ревью, мені люди так само намагалися сказати що у мене помилки, бо ревьювери були не в контексті.Помилка №2.
Інколи ChatGPT по різному інтерпретує як він хоче використовувати Markdown для відповідей. Я бачив 3 варіанта. Ідеальний варіант для мене, коли ГПТ знаходить заголовки сам, і форматує більш менш як потрібно текст, виділяючи ідентифікатори сам. Другий варіант, коли він лише забував виділяти заголовки, але ідентифікатори та блоки коду були правильно розпізнані. І третій варіант коли він просто відповідав форматованим текстом. Це все при явному проханню мати Markdown формат відповіді. Ця рандомізація була кожну нову сесію, і прив’язана до діалогу із ГПТ.
Помилка №3.
Інколи, десь на 10 відповіді, чи втомившись, чи через особливості тексту книги, який дуже ретельно пояснював, буквально розжовуючи, ChatGPT починав формувати чек-ліст, та список тверждень замість перекладу. Це дуже дратувало, я тоді йшов до Google Translate, перекладав там і редагував руками текст.
Помилка №4.
Можливо через те що текст доволі унікальний, і має лише оригінал на японській, та 1 переклад на англійскій, ChatGPT якось запам’ятала не лише текст, а ще й код, або через те що текст написаний дуже детально, із інструкціями що конкретно людям робити, то в кінці параграфа, ChatGPT додавав код. Цей код був майже такий самий як в книзі. Це майже помилка №3, але в якомусь іншому форматі. Це доволі рідка помилка, не можу сказати як її відтворити, але вона стабільно була у мене при перекладі конкретної книги.
В цілому я можу сказати що мені ChatGPT допоміг, але ці помилки не дають мені віри що це можна надійно автоматизувати. Як я казав і раніше, це для мене не є проблемою. Поки люди які більше ніж я працювали із ЛЛМ кажуть що я повинен більше специфікувати в промпті, але я не дуже бачу практичного сенсу, бо під кожну статтю налаштовувати промпт це начебто оверкіл, тому що я редагую так і так. Подивимось що буде через деякий час.
-
LSTM або Transformer як «пакувальник шкідливого ПЗ»
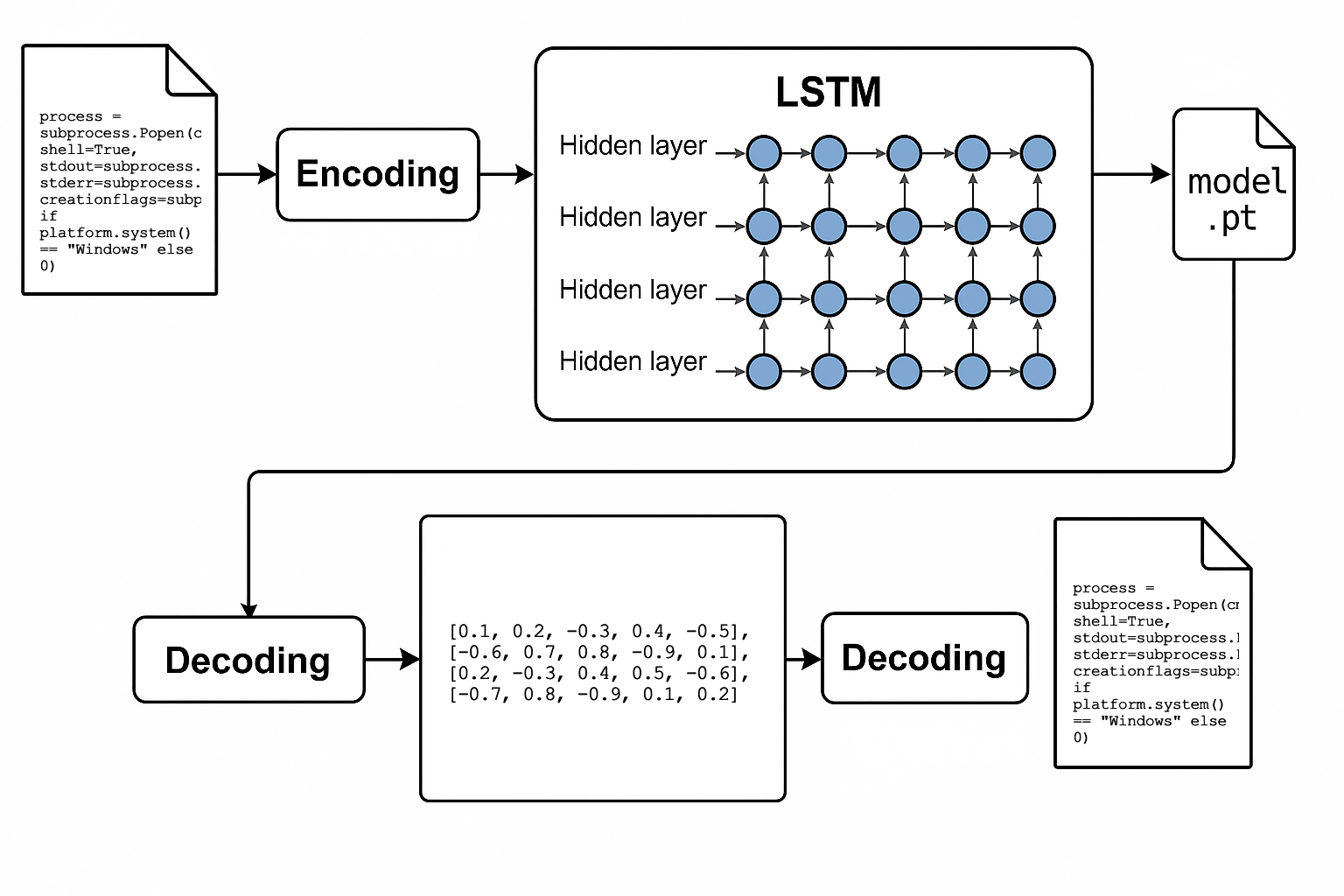
Приховування шкідливого коду в AI-моделях
Ідея використання AI-моделей для приховування шкідливого коду є не лише теоретичною — вже існують дослідження, які доводять її практичну здійсненність. Один із прикладів — техніка EvilModel, представлена у 2021 році, яка полягає у вбудовуванні шкідливого ПЗ безпосередньо в параметри нейронної мережі.
Експерименти продемонстрували вражаючі можливості цього методу. У популярній моделі AlexNet, розміром 178 МБ, дослідники успішно вбудували 36,9 МБ шкідливого коду — це приблизно 20% від ваг мережі — при цьому точність класифікації зображень знизилась менш ніж на 1%. У ще більш екстремальних тестах, де шкідливий код займав до 50% нейронів прихованого шару, спостерігалось лише незначне зниження точності — мережа зберегла 93,1% від початкової продуктивності.
Важливо, що такі моделі легко обходять антивірусні сканери.
-
Шаблони використання LLM - Шаблон генератора візуалізацій
Це десята стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 2. Автоматизатор виводу
- 3. Перевернута взаємодія
- 4. Шаблон персона
- 5. Шаблон уточнення питання
- 6. Шаблон альтернативні підходи
- 7. Шаблон когнітивного верифікатора
- 8. Шаблон список фактів для перевірки
- 9. Шаблон нескінченної генерації
Шаблон генератора візуалізацій
Намір і контекст
Мета цього шаблону полягає у використанні генерації тексту для створення візуалізацій. Багато концепцій легше зрозуміти у форматі діаграми або зображення. Мета цього шаблону полягає у створенні шляху для інструменту для створення зображень, пов’язаних з іншими результатами. Цей шаблон дозволяє створювати візуалізації шляхом створення вхідних даних для інших відомих інструментів візуалізації, які використовують текст як вхідні дані, таких як Graphviz Dot або DALL-E. Цей шаблон може забезпечити більш повний та ефективний спосіб передачі інформації, поєднуючи сильні сторони інструментів генерації тексту та візуалізації.
Мотивація
LLM зазвичай створюють текст і не можуть створювати зображення. Наприклад, LLM не може намалювати діаграму для опису графіка. Шаблон Генератор візуалізацій долає це обмеження, генеруючи текстові дані у правильному форматі для підключення до іншого інструменту, який генерує правильну діаграму. Метою цього шаблону є покращення результату LLM та зробити його візуально привабливішим і легшим для розуміння користувачами. Використовуючи текстові дані для створення візуалізацій, користувачі зможуть швидко зрозуміти складні концепції та взаємозв’язки, які може бути важко осягнути лише за допомогою тексту.
-
Шаблони використання LLM - Шаблон нескінченної генерації
Це дев’ята стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 2. Автоматизатор виводу
- 3. Перевернута взаємодія
- 4. Шаблон персона
- 5. Шаблон уточнення питання
- 6. Шаблон альтернативні підходи
- 7. Шаблон когнітивного верифікатора
- 8. Шаблон список фактів для перевірки
- 10. Шаблон генератора візуалізацій
Шаблон нескінченної генерації
Намір і контекст
Мета цього шаблону полягає в автоматичній генерації серії результатів (які можуть здаватися нескінченними) без необхідності кожного разу повторно вводити запит генератора. Мета полягає в тому, щоб обмежити обсяг тексту, який користувач повинен ввести для отримання наступного виводу, виходячи з припущення, що користувач не хоче постійно повторно вводити запит. У деяких варіаціях метою є дозволити користувачеві зберегти початковий шаблон запиту, але додати до нього додаткові варіації шляхом додаткових уточнень перед кожним згенерованим виводом.
Мотивація
Багато завдань вимагають повторного застосування одного й того ж запиту для багатьох концепцій. Наприклад, генерація коду для операцій створення, читання, оновлення та видалення (CRUD) для певного типу сутності може вимагати застосування одного й того ж запиту до кількох типів сутностей. Якщо користувач змушений повторно вводити запит знову і знову, він може припуститися помилок. Шаблон нескінченної генерації дозволяє користувачеві повторно застосовувати запит, з подальшим введенням або без нього, для автоматизації генерації кількох виходів за допомогою заздалегідь визначеного набору обмежень.
-
Шаблони використання LLM - Шаблон список фактів для перевірки
Це восьма стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 2. Автоматизатор виводу
- 3. Перевернута взаємодія
- 4. Шаблон персона
- 5. Шаблон уточнення питання
- 6. Шаблон альтернативні підходи
- 7. Шаблон когнітивного верифікатора
- 9. Шаблон нескінченної генерації
- 10. Шаблон генератора візуалізацій
Шаблон список фактів для перевірки
Намір і контекст
Намір цього шаблону полягає в тому, щоб гарантувати, що велика мовна модель (LLM) виводить список фактів, які присутні у відповіді та становлять важливу частину тверджень у ній. Цей список фактів допомагає користувачу зрозуміти, на яких фактах бо припущеннях ґрунтується відповідь. Користувач може потім провести відповідну перевірку цих фактів або припущень, щоб підтвердити достовірність відповіді.
Мотивація
Поточна слабкість великих мовних моделей полягає в тому, що вони часто швидко і з великим захопленням генерують переконливий текст, який є неправильним. Ці помилки можуть мати різні форми — від вигаданих статистичних даних до некоректних номерів версій бібліотек програмного забезпечення, чи неіснуючих книг, академічних статей. Однак через переконливий характер згенерованого тексту користувачі можуть не проводити належної перевірки для визначення його достовірності.
-
Що працює (а що ні) при продажу формальних методів!
Орігінальна стаття Майка Додса від 8 травня 2025 року про те що допомогає продавати формальні методи для мене дуже інтимна, так як вона говорить про дуже делікатні і важливі речі - як розмовляти про важливість формальних методів. Тому питання - перекладати, чи не перекладати для мене взагалі не стояло.
Ця стаття розпочала своє життя як доповідь, яку я провів наприкінці 2024 року.
Я люблю формальні методи — варто сказати це на початку, тому що ця стаття здебільшого про те, що не працює при спробах реалізувати проєкти з формальними методами. За останні 20 років формальні методи суттєво розвинулись, і я з гордістю можу сказати, що компанія Galois зробила свій внесок у цей успіх. Я зробив багато помилок під час планування та реалізації проєктів із формальними методами. Хотілося б, щоб інші змогли уникнути тих пасток, у які я потрапив, і, можливо, зробили б інші — більші й цікавіші — помилки.
-
Побрехенькі про авіацію у які вірять програмісти
Це переклад статті з 2025 року про неявні припущення які робили програмісти при праці в авіації.
У компанії FlightAware наше програмне забезпечення має коректно обробляти всілякі дивні й непередбачувані ситуації. Хоча нам, інженерам, хотілося б, щоб авіаційні дані були чистими та добре стандартизованими, реальний світ це бардак.
Існує безліч припущень, які можна зробити під час проєктування типів даних і схем для авіаційної інформації - і багато з них виявляються хибними. Ось перелік хибних уявлень, у дусі класичної статті Патріка Маккензі про імена, які можна мати про авіацію. Хоча деякі з них - це просто поширені міфи, деякі реально створювали проблеми нашим клієнтам, а інші - роками завдавали труднощів і в наших власних системах.
-
Побрехенькі про імена у які вірять програмісти
Це переклад доволі старої і дуже відомої статті з 2010 року про неявні припущення які роблять програмісти при праці із іменами.
Сьогодні Джон Ґрем-Каммінґ написав статтю, в якій поскаржився на те, що комп’ютерна система, з якою він працював, визначила його прізвище як таке, що містить неприпустимі символи. Звісно, це не так - адже будь-що, що людина називає своїм іменем, за визначенням є правильним способом її ідентифікації. Ця ситуація закономірно обурила Джона, і він має на це повне право, бо імена - це основа нашої ідентичності, майже за визначенням.
-
Шаблони використання LLM - Шаблон когнітивного верифікатора
Це сьома стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 2. Автоматизатор виводу
- 3. Перевернута взаємодія
- 4. Шаблон персона
- 5. Шаблон уточнення питання
- 6. Шаблон альтернативні підходи
- 8. Шаблон список фактів для перевірки
- 9. Шаблон нескінченної генерації
- 10. Шаблон генератора візуалізацій
Шаблон альтернативні підходи
Намір і контекст
Дослідниками описано, що LLM часто можуть думати краще, якщо питання розділено на додаткові запитання, які дають відповіді, об’єднані в загальну відповідь на початкове запитання. Намір шаблону полягає в тому, щоб змусити LLM завжди ділити питання на додаткові запитання, які можна використовувати для надання кращої відповіді на вихідне запитання.
Мотивація
У шаблону когнітивного верифікатора є подвійна мотивація:
- Люди можуть спочатку ставити запитання занадто високого рівня, щоб дати конкретну відповідь, без залучення додаткових уточнювань, через незнайомість користувача із доменом, лінь у швидкому введенні або невпевненість у правильному формулюванні запитання.
- Дослідження показали, що LLM часто можуть працювати краще, якщо використовувати запитання, яке підрозділяється на окремі питання.
-
Simple use case for property based testing
Here we go property-based testing. It’s usually topic which does not have too much discussion on the Internet, and when it is discussed there not much practical aspects to it. It’s relatively well known that you should wrote your invariants and test agains them. This is all fine, but does not give you idea about what exactly these properties of your models are.
So here our problem. The path normalization. This is art of conversion of paths
road/path/../to/hell/toroad/to/hell, orskip/me/./if/you/cantoskip/me/if/you/can, or../../../only/forward/no/backwards. Basically simplification of paths. That can be very tricky business. For example,././testis justtest, or/../some/is really wrong path, but we have to leave it as is because it appear as absolute path. -
Думки про безпеку аплікацій
Мене вже давно турбує питання, що, як на мене, спеціалісти з безпеки недостатньо добре працюють у напрямку популяризації своїх ризиків та навчання людей побудові безпечних рішень.
Мій тезис полягає в тому, що фахівці з безпеки просто не бачать складності навчального процесу і не враховують педагогічні досягнення, які ми бачимо і до яких звикли в інших сферах ІТ. Ми звикли до цього комфорту і не хочемо напружуватися більше, ніж потрібно. А потреба в безпеці не завжди яскраво виражена в нашій роботі, що створює конфлікт інтересів.
Нижче я приведу декілька прикладів які на мою думку показують що спільнота мов програмування вчить своїх людей краще ніж безпечники.
-
Шаблони використання LLM - Шаблон альтернативні підходи
Це шоста стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 2. Автоматизатор виводу
- 3. Перевернута взаємодія
- 4. Шаблон персона
- 5. Шаблон уточнення питання
- 7. Шаблон когнітивного верифікатора
- 8. Шаблон список фактів для перевірки
- 9. Шаблон нескінченної генерації
- 10. Шаблон генератора візуалізацій
Шаблон альтернативні підходи
Намір і контекст
Мета шаблону полягає в тому, щоб LLM завжди пропонував альтернативні способи виконання завдання, щоб користувач не використовував лише ті підходи, з якими він знайомий. LLM може пропонувати альтернативні підходи, які завжди змушують користувача думати про те, що він робить, і визначати для себе, чи це найкращий підхід для досягнення мети. Крім того, вирішення завдання може проінформувати користувача або навчити його альтернативним концепціям для подальшої роботи.
Мотивація
Люди часто страждають від когнітивних упереджень, які змушують їх обирати певний підхід до вирішення проблеми, навіть якщо це не є правильним або «найкращим» підходом. Більше того, люди можуть не знати про альтернативні підходи до тих, що вони використовували в минулому. Мотивація шаблону Альтернативні підходи полягає в тому, щоб забезпечити обізнаність користувача про альтернативні підходи для вибору кращого підходу до вирішення проблеми шляхом усунення його когнітивних упереджень.
-
OpenWebIndex - Европейський індекс вебу
У вересні 2022 року партнери розпочали реалізацію проєкту ЄС OpenWebSearch.eu — першого проєкту, який ЄС профінансував для запуску незалежного веб-пошуку.
Проєкт виник як відповідь на занепокоєння ЕС щодо дисбалансу на ринку пошукових систем. Веб-пошук є основою цифрової економіки, але він перебуває під контролем обмеженої кількох гравців, таких як Google, Microsoft, Baidu або Yandex, які всі знаходяться за межами ЕС. Таким чином, інформація як суспільне благо, з вільним, неупередженим і прозорим доступом, більше не знаходиться під контролем европейского суспільства. Цей дисбаланс становить загрозу для демократії в межах ЕС та обмежує інноваційний потенціал дослідницького простору та економіки самого ЕС. Через це ЕС вирішив проінвестувати в розвиток незалежної, більш децентралізованої інфраструктури для пошуку в мережі Інтернет.
-
Мексика үкіметінде ашық кодты қолдану тәжірибесі
Бұл мақаланың аудармасы LWN.NET сайтынан.
Ашық бастапқы кодты бағдарламалық қамтамасыз етуді, үкіметтің бағдарламаны қабылдағаны әртүрлі жетістіктер мен сәтсіздіктерге ұшырады. Ашық код айқын таңдау сияқты көрінгенімен, үкіметтер түрлі себептермен еркін және ашық бастапқы кодты бағдарламалық қамтамасыз етуді (FOSS) қабылдауға күтпеген қарсылық көрсетуі мүмкін. Федерико Гонсалес Уэйт SCALE 22x шарасында Open Government конференциясында өзінің Мексика үкіметімен жұмыс тәжірибесін баяндады. Ол бірнеше жобаларды басқарды, олардың мақсаты меншік құқығындағы, жиі қанаушылық сипаттағы бағдарламалық компаниялардан көшу болатын, кейбір табыстармен және сәтсіздіктермен.
Гонсалес Уэйт өзінің мексикалық/киви екенін айтты (
"біздей адамдар көп емес", деді ол ұялып), және Мексика үкіметінде тоғыз немесе он жыл жоғары лауазымдарда жұмыс істегенін айтты,"ашық кодты енгізуді ілгерілеткен". Ол, басқалармен қатар, Сыртқы істер министрлігінің CTO-сы болды;"Бүгінде мексикалықтардың электронды төлқұжаттары бар болса, бұл менің жұмысымның арқасы". Бұл оның басқарған жобаларының бірі болды, және оның бір бөлігі ашық бастапқы кодты бағдарламалық қамтамасыз етумен жасалды, бұл көпшілікті таң қалдырғанын айтты. Ол сондай-ақ президент Андрес Мануэль Лопес Обрадор кезіндегі ұлттық стратегия офисінде жұмыс істеді және кейінірек Мексиканың Ұлттық зерттеулер мен инновациялар орталығының бас директоры болды.Барлық қызметтерінде ол үкіметте ашық кодты қолдануды қолдады; осындай ауқымда өзгеріс енгізу әрқашан оңай емес, деп атап өтті ол. Жақында президент ауысқаннан кейін (Клаудия Шейнбаумға) ол үкіметтен кетті және қазір
"адамдарға өздерінің ашық кодқа көшуін жүзеге асыруға көмектеседі", әрі жаңа негізгі тенденцияларды бақылап отыр. Ол сұрақтарға соңында жауап беретінін айтты, бірақ кейбір сұрақтарға құпиялық міндеттемелері себебінен жауап бере алмауы мүмкін, дегенмен"ол мемлекеттік қызметкер болмағандықтан, еркін сөйлеу мүмкіндігі көбірек"екенін атап өтті. -
MagicMapper: The fork of AutoMapper
Recent changes in the AutoMapper license, and the waves which this send across .NET chats and subreddits make me think. Why even look for alternatives to AutoMapper? I really have erratic feelings about that and it rubs me wrong way. AutoMapper was free and useful software for a long time. Jimmy really do great job maintainig it, and even coming out as guy who want a bit more money was done in very professional way.
So why not even create a fork given that AutoMapper have MIT license?
Is across whole .NET community not enough developers who have two things, a bit of free time, and a bit of charitable character to maintain things. Why send ripples across bunch of products and perform meaningless rewrites? If you think about it, if you want replace AutoMapper with Mapperly you somehow should justify it. Prefereably as business developers say, that should have business impact. Some fearmongering that “maybe” something happens is not really a justification, because obviosuly Mapperly after sometime may go out of OSS business. Maybe not, but we don’t know. Is rewriting to anything else, not nescessary Mapperly obviously, a reasonable investment, or you can just fork existing working product, with excellent maintainance infrastructure and call it a day.
But just forking is not maintaining!
Yes, sure. But how often you expect anything new from AutoMapper as was super happy with new release? From what I know Jimmy don’t really cooperate much with outsiders. That’s his project, cannot blame him on choosing safe way to engage with users. What kind of improvements do you really expect? If you have one, and want spend cycles discussing how you can improve something, let me know.
Now to maintaining. I really don’t see this as high maintainaince project. You can really go very far with allowing people contribute and submit PR + tests. Existing tests very solid. Just adopt policy to never change existing tests and never break them. That’s easy. Improving would be harder, but you know, who cares… That’s maintainance and we in .NET and not in JavaScript where Mark’s Zuckerberg shouting ‘Move fast and break everything’ from every corner.
I want improvements!
So do I. My personal wish for AutoMapper is to be able use it in NativeAOT. Honesly given it’s very liberal use of reflection, I did not try to do that on my NativeAOT fixing spree. I thinking that Jimmy would not want to re-engeneer library to make it support NativeAOT. Maybe I was wrong, but given that I have perception that it would not answer I do not even try. Probably this is golden opportunity. Maybe that allow me to make NativeAOT more friendly to corporate codebases. I know that NativeAOT is painful, and the more libraries will support it in some fashion, the better for everybody. I never understand some decisions which Microsoft developers did back then, and now I painfully realize that this is proper decisions, even if NativeAOT is not that extreme and agressive as it can be. Kudos for caring about community THAT much.
So in short, expect some source generator experiments. I know that support everything would be impossible, but let’s try to poke that. That would be in separate branch probably.
Statement
I create fork, and call it MagicMapper, it’s on Nuget, I do not fully migrate on it my projects, but I will.
I at minimum plan to maintain this fork for an year. Most likely more. I’m much more liberal to transferring ownership to the project to other, so in case I would be missing or unable to, I think it would be possible to continue work on the project for anybody else, without disruption by other.
I do try my best to have spirit of OSS running on this project. I want that fork to be solution for independent developers. For somebody to remember, I hope it can be revitalization of Alt.Net movement.
Personally I more dislike AutoMapper then like it. The only reason why I dislike it, is that it breaks tooling and if using without moderatin it’s easy to make things worse. That don’t reason to abandon library in my opinion, we should preserve too. What I learn during my years in software development is that rewriting is always worst decision then evolution.
What about other projects?
In addition to AutoMapper there MediatR and MassTransit. Honesly I never think about forking them, but jokes from my friends that I fork everything what can be forked sometimes make sense. I think I have limited time to maintain, and cannot do that alone, so if somebody think that’s worth it, I may reconsider my involvement. AutoMapper can live on life support, but MediatR is next level, and MassTransit is definitely even more harder.
Acknoledgment
I fully aknowledge hard work which Jimmy Bogard did on AutoMapper. I would like to thank you him! I personally don’t envision how my fork can endanger his future business or AutoMapper as commercial thing. I think there can be space for both options in the .NET ecosystem.
Call for help
I still not done transferring documentation to some other location, and make sure that all links point to proper location, and other housekeeping things. If you want help, go to Github and start hacking.
-
Шаблони використання LLM - Шаблон уточнення питання
Це п’ята стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 2. Автоматизатор виводу
- 3. Перевернута взаємодія
- 4. Шаблон персона
- 6. Шаблон альтернативні підходи
- 7. Шаблон когнітивного верифікатора
- 8. Шаблон список фактів для перевірки
- 9. Шаблон нескінченної генерації
- 10. Шаблон генератора візуалізацій
Шаблон уточнення питання
Намір і контекст
Цей шаблон залучає LLM до процесу розробки запиту. Мета цього шаблону полягає в тому, щоб розмовний LLM завжди пропонував потенційно кращі або більш рафіновані запитання, які користувач міг би поставити замість свого початкового запитання. Використовуючи цей шаблон, LLM може допомогти користувачеві знайти правильне питання, щоб отримати точну відповідь. Крім того, LLM може допомогти користувачеві знайти інформацію або досягти його мети за меншу кількість взаємодій з користувачем, ніж якби користувач використовував підказки методом проб і помилок.
Мотивація
Якщо користувач ставить запитання, можливо, він не є фахівцем у цій галузі та може не знати, як найкраще сформулювати запитання, або не знати про додаткову інформацію, яка допоможе сформулювати запитання. LLM часто зазначають обмеження щодо відповіді, яку вони надають, або запитують додаткову інформацію, щоб допомогти їм отримати більш точну відповідь. LLM може також висловити припущення, які він зробив, надаючи відповідь. Мотивація полягає в тому, що цю додаткову інформацію або набір припущень можна використати для створення кращого підказки. Замість того, щоб вимагати від користувача переварити та перефразувати своє підказку з додатковою інформацією, LLM може безпосередньо вдосконалити підказку, щоб включити додаткову інформацію.
-
Досвід із використання відкритого коду в уряді Мексики
Це переклад статті із LWN.NET
Прийняття урядами програмного забезпечення з відкритим вихідним кодом мало як злети, так і падіння. Хоча відкритий код здається очевидним вибором, виявляється, що уряди можуть бути дивно опірними до використання вільного ПЗ з відкритим кодом (FOSS) з різних причин. Федеріко Гонсалес Уейт виступив на конференції Open Government на SCALE 22x у Пасадені, Каліфорнія, щоб згадати свій досвід роботи із та на мексиканський уряд. Він очолював декілька проєктів, що передбачали перехід від пропріетарних, часто хижацьких, програмних компаній, з певним успіхом і також невдачами.
Гонсалес Уейт почав з того, що він є мексиканцем/ківі (
"не так много таких як ми", сказав він зашарівшись), який провів дев’ять або десять років на високих посадах у мексиканському уряді,«просуваючи впровадження відкритого коду». Серед іншого він був CTO у Міністерстві закордонних справ;«Я фактично відповідаю за те, що сьогодні мексиканці мають електронні паспорти». Це був один з проєктів, яким він керував, і частина його була виконана за допомогою ПЗ з відкритим кодом, що люди вважають дивовижним, за словами Гонсалеса Уейта. Він працював в офісі національної стратегії при президенті Андресі Мануелі Лопесі Обрадорі, а згодом став генеральним директором Національного центру досліджень і інновацій Мексики.У всіх своїх ролях він виступав за використання відкритого коду в уряді; бути «змінювачем» такого масштабу завжди нелегко, зазначив він. Він залишив уряд після недавньої зміни президента (на Клаудію Шейнбаум) і зараз працює
«допомогаючи людям здійснювати власні трансформації»до відкритого коду, водночас слідкує за наступними великими тенденціями. Він зазначив, що відповість на запитання в кінці, але можливо не зможе відповісти на всі через конфіденційні зобов’язання, проте він«вже не є публічним посадовцем, тому це дає мені більше свободи говорити відкрито». -
Шаблони використання LLM - Шаблон персона
Це четверта стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 2. Автоматизатор виводу
- 3. Перевернута взаємодія
- 5. Шаблон уточнення питання
- 6. Шаблон альтернативні підходи
- 7. Шаблон когнітивного верифікатора
- 8. Шаблон список фактів для перевірки
- 9. Шаблон нескінченної генерації
- 10. Шаблон генератора візуалізацій
Шаблон персона
Намір і контекст
У багатьох випадках користувачі бажають, щоб результат LLM завжди мав певну точку зору або перспективу. Наприклад, може бути корисно провести перевірку коду так, ніби LLM є експертом з безпеки. Намір цього шаблону полягає в тому, щоб надати LLM «особистість», яка допомагає вибирати які типи результатів генерувати та на яких деталях зосереджуватися.
Мотивація
Користувачі можуть не знати, на яких видах результатів або дрібницях важливо зосередитися LLM для досягнення поставленого завдання. Однак вони можуть знати роль або тип людини, яку вони зазвичай просять допомогти з цими речами. Шаблон Персона дозволяє користувачам висловлювати, з чим їм потрібна допомога, не знаючи подробиць очікуваних результатів.
-
Шаблони використання LLM - Перевернута взаємодія
Це третя стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 2. Автоматизатор виводу
- 4. Шаблон персона
- 5. Шаблон уточнення питання
- 6. Шаблон альтернативні підходи
- 7. Шаблон когнітивного верифікатора
- 8. Шаблон список фактів для перевірки
- 9. Шаблон нескінченної генерації
- 10. Шаблон генератора візуалізацій
Перевернута взаємодія
Намір і контекст
Ви хочете, щоб LLM ставив запитання, щоб отримати інформацію, необхідну для виконання деяких завдань. Таким чином, замість того, щоб користувач керував розмовою, ви хочете, щоб LLM керував розмовою, щоб зосередити її на досягненні конкретної мети. Наприклад, ви можете захотіти, щоб LLM провів для вас короткий тест або автоматично ставив запитання, поки не отримає достатньо інформації для створення сценарію розгортання вашої програми в певному хмарному середовищі.
Мотивація
Замість того, щоб користувач керував бесідою, LLM часто має знання, які може використовувати для більш точного отримання інформації від користувача. Мета шаблону Flipped Interaction полягає в тому, щоб перевернути потік взаємодії, щоб LLM ставив користувачеві запитання для досягнення бажаної мети. LLM часто може краще вибрати формат, кількість і зміст взаємодій, щоб забезпечити досягнення мети швидше, точніше та/або використовуючи знання, якими користувач може (спочатку) не володіти.
-
Шаблони використання LLM - Автоматизатор виводу
Це друга стаття стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 1. Шаблон створення сленгу
- 3. Перевернута взаємодія
- 4. Шаблон персона
- 5. Шаблон уточнення питання
- 6. Шаблон альтернативні підходи
- 7. Шаблон когнітивного верифікатора
- 8. Шаблон список фактів для перевірки
- 9. Шаблон нескінченної генерації
- 10. Шаблон генератора візуалізацій
Автоматизатор виводу
Намір і контекст
Мета цього шаблону полягає в тому, щоб LLM генерував скріпт або інший артефакт автоматизації, який може автоматично виконувати будь-які кроки, які він рекомендує виконати як частину свого виводу. Мета полягає в тому, щоб зменшити ручні зусилля, необхідні для впровадження будь-яких рекомендацій від LLM.
Мотивація
Результатом LLM часто є послідовність кроків, які користувач повинен виконати. Наприклад, прохаючи LLM створити конфігураційний скріпт на Python, LLM може запропонувати кілька файлів які треба модифікувати та зміни, які слід застосувати до кожного файлу. Однак змушувати користувачів постійно виконувати кроки вручну, продиктовані результатом LLM, це дуже виснажливо і цей процес буде схильним до помилок.
-
Шаблони використання LLM - Шаблон створення сленгу
Це перша стаття із серії яка описує шаблони будування запитів до LLM систем. Інші статті в серії
- 2. Автоматизатор виводу
- 3. Перевернута взаємодія
- 4. Шаблон персона
- 5. Шаблон уточнення питання
- 6. Шаблон альтернативні підходи
- 7. Шаблон когнітивного верифікатора
- 8. Шаблон список фактів для перевірки
- 9. Шаблон нескінченної генерації
- 10. Шаблон генератора візуалізацій
Шаблон створення сленгу
Намір і контекст
Під час спілкування із LLM, користувач може створити запит через альтернативний діалект мови, такий як скорочені текстові позначення для графів, чи опис станів і переходів станів для кінцевої машини, чи набір команд для швидкої автоматизації тощо. Шаблон пояснює семантику цієї альтернативної мови LLM, щоб користувач міг писати майбутні запити, використовуючи цей новий сленг та її семантику.
Мотивація
Багато проблем, структур або інших ідей, висловлених у запиті, можуть бути виражені більш стисло, однозначно та чітко мовою, відмінною від побутової української (або іншої мови, яка використовується для взаємодії з LLM). Однак, щоб отримати результат на основі іншого професійного сленгу, LLM повинен розуміти його семантику.
-
Італійській опенсурс
Шлях Італії до відкритого коду
Історія використання відкритого коду в Італії серед держустанов починається із публікації змін до DECRETO-LEGGE 22 giugno 2012, n. 83. Ці зміни явно прописали можливість використовування програмного забезпечення із відкритим кодом. Ці зміни не декларували потребу використовувати саме відкритий код, але вимагали проводити оцінку ефективності використання відкритого коду у порівнянні із пропрієтарними рішеннями. Пізніше, після публкації цього закону, у листопаді 2012 Агенція Цифрової Італії (L’Agenzia per l’Italia Digitale) почала закликати усіх зацікавлених прийняти участь у процесі будування рекомендацій для виконування данних змін. На той час, в Італії вже було правило що вимагало різні держустанови ділитися між собою розробленими для них, чи куплене їм програмне забезпечення. Це правило дуже схоже до юрідичних правил ліцензування відкритого коду, де будь які зміни становляться публічними для інших.
-
Reflection on Evaluating Human Factors beyond likes of code.
I’m very glad that more articles like this come out of academia. If you haven’t read it yet, please do, as my thoughts are based on this article.
Personally as industry worker I suffered a lot from perceived misinterpretation of some usability and easy-of-use metrics for programming languages. Also blanket ignoring that some of my friends and coworkers have problem with understanding of some PL concepts. Also even if I totally agree with message, my perception is that message of article would pass by intended audience and things become “business as usual”. I writing this post, to probably fuel some discussion.
-
Сертіфікований перевіряльник типів
У цьому прикладі, ми побудуємо сертифікований перевіряльник типів для простої мови виразів яка має лише 2 типа натуральні числа і логічні значення, і лише дві операції додавання і логічне І.
Зауваження: цей приклад базується на прикладі із книги Certified Programming with Dependent Types Адама Чіліпала і прикладу із репозіторію Lean4.
-
Вартість програмного забезпечення з відкритим кодом
Це переклад статті від Гарвадської школи бізнеса. Орігінал тут
Зміст
-
Порівняння перевірки запозичень Rust із аналогом у C#
Це переклад орігінальної статті із англійської. Усі дяки туди!
Хвилинку! C# має засіб перевірки запозичень?
Дивіться: класичний приклад безкоштовної безпеки пам’яті у Rust…
// error[E0597]: `shortlived` does not live long enough let longlived = 12; let mut plonglived = &longlived; { let shortlived = 13; plonglived = &shortlived; } *plonglived;…портуючи на C#:
// error CS8374: Cannot ref-assign 'shortlived' to 'plonglived' because // 'shortlived' has a narrower escape scope than 'plonglived' var longlived = 12; ref var plonglived = ref longlived; { var shortlived = 13; plonglived = ref shortlived; } _ = plonglived; -
Learning programming by immersion
This is translation of post in Ukrainian
I just read article about Stephen Krashen’s theory on second language acquisition and it struck me with similarities which I see in the learning how we build software. Maybe that can be said about any skill acquisition, but given that programming languages and natural languages have some similarities I would try to speculate a bit.
-
Вивчення програмування через занурення
Я щойно прочитав статтю про теорію Стівена Крашена щодо оволодіння другою мовою, і мене вразили паралелі, які я бачу у навчанні того, як ми будуємо програмне забезпечення. Можливо, це можна сказати про будь-яке оволодіння навичками, але, зважаючи на те, що мови програмування та природні мови мають певні схожості, я спробую трохи пофантазувати.
-
Швейцарский закон: Открытый исходный код по умолчанию
Данная статья, является переводом с украинского. Также есть черновик перевода на казахский
Открытый исходный код и открытые правительственные данные
Через весь интернет пролетела новость, что швейцарское правительство теперь должно выкладывать все программные продукты, под лицензиями открытого кода. Это меня очень заинтересовало, но из-за того что Швейцария не англоязычная страна, то информации о том что именно было сделано, было очень мало. А как известно, анализ законов это не о том, что публикуют в новостях. Надо читать сами законы, пусть и в переводе, и стараться самостоятельно делать выводы. Также любому разработчику конечно интересны не только законы, но и код. Где этот магический открытый исходный код. Поэтому я постарался найти достаточно информации чтобы было и что почитать и что поклацать.
-
Ашық код ретінде қабылданған: бұл швейцариялық заң.
Бұл мақала украин тілінен аударылған. Сонымен қатар, орыс тілінде аудармасы бар.
Ашық бастапқы код және ашық үкіметтік деректер
Интернетте швейцариялық үкіметтің енді барлық бағдарламалық өнімдерді ашық код лицензиясымен жариялау керектігі туралы жаңалық тарады. Бұл маған өте қызықты болды, бірақ Швейцария ағылшын тілді ел болмағандықтан, нақты не істелгені туралы ақпарат өте аз болды. Белгілі болғандай, заңдардың талдауы жаңалықтарда жарияланатын нәрсе емес. Заңдардың өзін оқу керек, аудармасында болса да, және өздігінен қорытынды жасауға тырысу керек. Сонымен қатар, кез келген әзірлеушіге тек заңдар ғана емес, код та қызықты. Сол сиқырлы ашық код. Сондықтан мен оқуға да, тексеруге де жеткілікті ақпарат табуға тырыстым.
-
Tokens in different languages
How different languages define tokens?
One guy ask in the chat, “how should I define tokens? should I combine token information with position in file?”. That’s simple question, and coming from C#, for me answer was obviously yes. But, I was curios how other languages define different tokens.
-
Відкритий код як усталено: це швейцарський закон
Відкритий вихідний код і відкриті урядові дані
Через увесь інтернет пролетіла новина що швейцарський уряд тепер повинен викладати усі програмні продукти, під ліцензіями відкритого коду. Це дуже мене зацікавило, але через те що Швейцарія не англомовна країна, то інформація про те що саме було зроблено, було дуже мало. А як відомо, аналіз законів це не про те що публікують у новинах. Треба читати самі закони, хай і у перекладі, та намагатися самостійно зробити висновки. Також будь якому розробнику звісно цікаві не тільки закони, а і код. Дей цей магічний відкритий код. Тому я спробував знайти достатньо інформації щоб було і що почитати і що потицяти.
-
Безкоштовні датасети із супутників!
Знайшов класний тред із супутниковою зйомкою. Що цікаво, вони усі безкоштовні. Тому якщо вас цікавить сучасна геодезія, або агрономія, або планування інфраструктури, думаю буде цікаво подивитися.
Найбільш часто використовувані безкоштовні багатоспектральні супутникові зображення:
- Sentinel 2
- Landsat-8
-
Придумана складність у програмуванні!
Студентам та джунам-фрілансерам присвячується.
За останні кілька років мені кілька разів доводилося чути від розробників різного рівня досвіду, але переважно початківців:
— Нещодавно я написав чудову, корисну, дуже складну програму
Де ці епітети – чудовий, корисний та дуже складний стояли в один ряд і мали означати якісь виключно цінні якості цього твору. Щодо слів чудовий, корисний, то в цьому немає сумніву, але те, що слова дуже складний в цьому ряду – це, звичайно, нісенітниця.
-
MSBuid як мова програмування!
Зі сторони виглядає що багато програмістів побоюються MSBuild і намагаются ніколи його не чіпати. Це на мою думку не дуже продуктивно. Багато цих страхів щодо MSBuild через те що у нього є свою, і досить незвична для програміста, термінологія. Я спробую показати що MSBuild це лише дінамічна мова програмування, досить чудернацька, але лише мова програмування. Можливо це полегшить читачу шлях його вивчення.
subscribe via RSS