LSTM або Transformer як «пакувальник шкідливого ПЗ»
Приховування шкідливого коду в AI-моделях
Ідея використання AI-моделей для приховування шкідливого коду є не лише теоретичною — вже існують дослідження, які доводять її практичну здійсненність. Один із прикладів — техніка EvilModel, представлена у 2021 році, яка полягає у вбудовуванні шкідливого ПЗ безпосередньо в параметри нейронної мережі.
Експерименти продемонстрували вражаючі можливості цього методу. У популярній моделі AlexNet, розміром 178 МБ, дослідники успішно вбудували 36,9 МБ шкідливого коду — це приблизно 20% від ваг мережі — при цьому точність класифікації зображень знизилась менш ніж на 1%. У ще більш екстремальних тестах, де шкідливий код займав до 50% нейронів прихованого шару, спостерігалось лише незначне зниження точності — мережа зберегла 93,1% від початкової продуктивності.
Важливо, що такі моделі легко обходять антивірусні сканери. Модель із вбудованим шкідливим кодом залишилась непоміченою всіма 58 рушіями системи VirusTotal. Це пояснюється тим, що шкідливе ПЗ, приховане в параметрах нейромережі, є розпорошеним та закодованим у числах з плаваючою комою, що не містять характерних послідовностей байтів, які виявляються традиційними системами виявлення на основі сигнатур.
Навмисне використання явища перенавчання
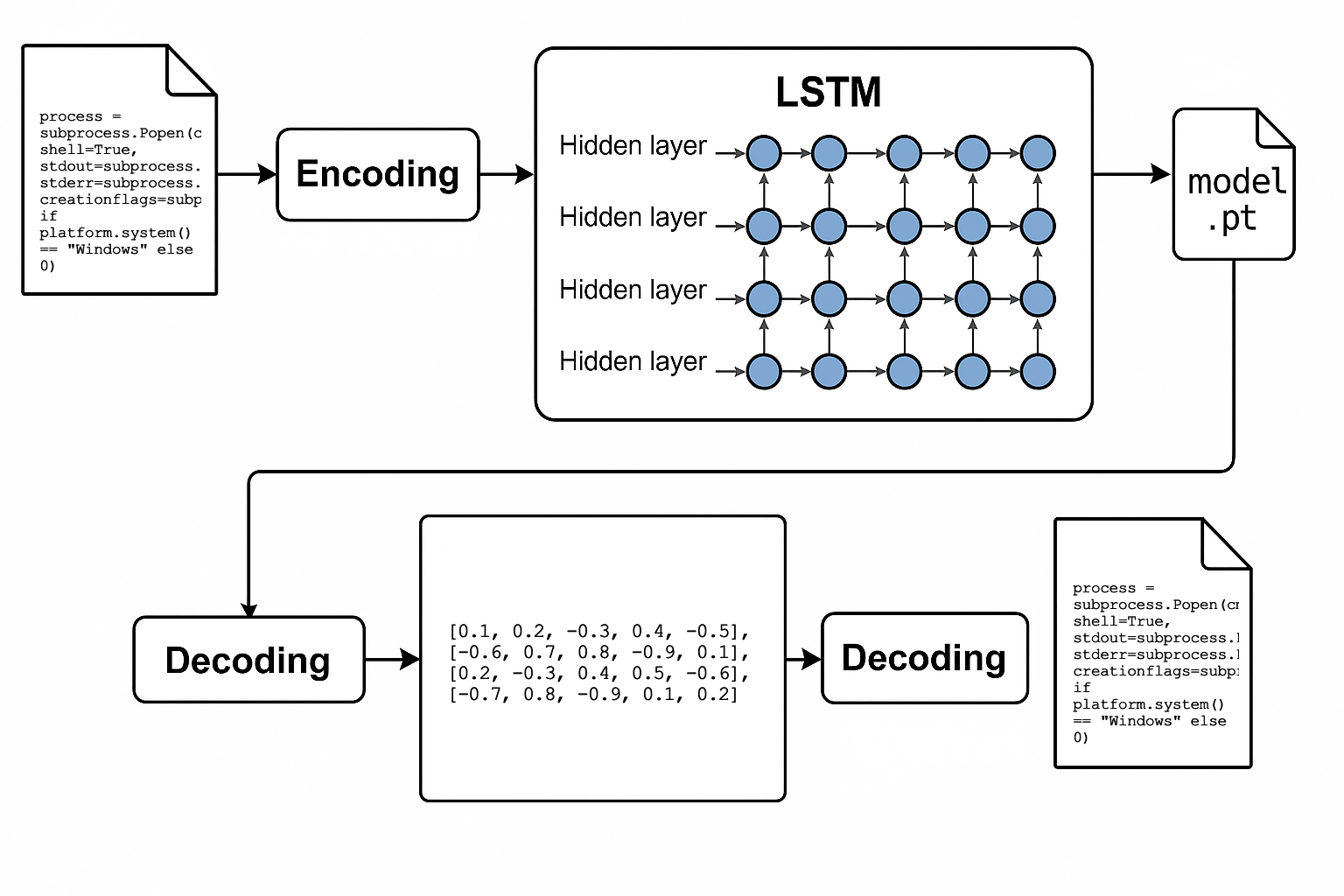
Альтернативним підходом до EvilModel є упакування повного коду програми в нейронну мережу шляхом навмисного використання явища перенавчання. Я розробив прототип з використанням PyTorch та LSTM-мережі, яку інтенсивно тренували на одному вихідному файлі доти, доки вона повністю не запам’ятала його вміст. Тривале навчання перетворює ваги мережі на контейнер для даних, які згодом можна реконструювати.
Ефективність цієї техніки було підтверджено шляхом генерації коду, ідентичного оригінальному, що перевірялось порівнянням контрольних сум SHA-256. Подібних результатів можна досягти також за допомогою інших моделей, таких як GRU або трансформери лише з декодером, що демонструє гнучкість цього підходу.
Перевага такого типу «пакувальника» полягає у відсутності типової поведінкової активності, яку могли б розпізнати традиційні антивірусні системи. Замість звичних операцій шифрування та розшифрування, процес «розпакування» відбувається як частина нормальної інференції нейронної мережі.
Виклики виявлення
Нейронна мережа як нетрадиційний пакувальник важко виявляється, оскільки для більшості аналітичних інструментів вона виглядає як звичайна бібліотека для обчислень AI. Лише на виході мережі з’являється готовий до виконання шкідливий код, що створює суттєві складнощі для типових антивірусних евристик.
Потенційно підозрілою поведінкою може бути запис згенерованого коду на диск, але навіть цього можна уникнути, застосовуючи техніки безфайлового шкідливого ПЗ, коли код генерується і виконується безпосередньо в пам’яті процесу.
Використання апаратних прискорювачів AI
Один із найцікавіших аспектів використання AI-моделей для приховування шкідливого ПЗ — це можливість задіяти спеціалізовані апаратні прискорювачі нейронних мереж, які є у багатьох сучасних пристроях (наприклад, Apple Neural Engine, GPU NVIDIA з Tensor Core).
Головна перевага такого підходу — мінімізація підозрілої поведінки на рівні CPU, оскільки інтенсивні обчислення виконуються на спеціалізованих чипах. Менеджери ресурсів або системи безпеки можуть не виявити нічого підозрілого, оскільки процес виглядає як звичайні AI-операції.
Більше того, типові методи динамічного аналізу (пісочниці) є неефективними проти обчислень, що виконуються на GPU або NPU, що значно ускладнює аналіз шкідливого ПЗ. Системи моніторингу процесів і ресурсів часто не мають механізмів для контролю операцій бібліотек машинного навчання, забезпечуючи шкідливому ПЗ додатковий рівень невидимості.
Технічні виклики для нападників
Попри численні переваги, цей підхід також пов’язаний із певними технічними викликами. Нападникам необхідно готувати моделі, сумісні з апаратним забезпеченням жертви, а також потенційно доставляти відповідні формати моделей, що вимагає додаткових зусиль. Однак сучасні фреймворки дозволяють конвертувати моделі між платформами, що робить це завдання здійсненним.
В результаті нейронні пакувальники можуть стати привабливою альтернативою традиційним методам приховування шкідливого ПЗ, подібно до історичних технік вбудовування коду у пам’ять GPU. Швидкий розвиток апаратного забезпечення для AI незабаром може перетворити цю техніку на серйозну загрозу кібербезпеці.
При розширенні цього прототипу пам’ятайте про використання бібліотеки safetensors, щоб уникнути проблем безпеки, таких як «pickle-атаки». Це лише дослідницький проект і не призначений для промислового використання. Використовуйте його виключно для освітніх і наукових цілей, а не для створення шкідливого програмного забезпечення.
Відповіді на ваші запитання після статті про пакування шкідливого програмного забезпечення
Дякую за позитивний відгук!
Я не очікував такого великого інтересу до мого першого блог-посту. Це був короткий дослідницький експеримент — ідея навмисно перенавчити LSTM або Transformer-модель, щоб «упакувати» в неї код, який згодом можна було б витягти. Концепція прийшла мені близько місяця тому, але лише нещодавно я знайшов час, щоб записати це та опублікувати.
Можливо, це не революційна ідея, але вона явно зайняла свою нішу — раніше ніхто не пропонував використовувати перенавчання(overfitting) з практичною метою, особливо у контексті шкідливого ПЗ. І саме це виявилось найцікавішим для спільноти.
Моя стаття здобула несподівану популярність. Після публікації на Reddit вона потрапила на головну сторінку r/MachineLearning. Станом на 1 липня:
- 79 000 переглядів
- 300 позитивних голосів (96%)
- 324 поширення
Дякую за кожен коментар, питання і критику. Мені приємно, що тема знайшла відгук у багатьох людей.
Відповіді на коментарі Reddit
Хочу тепер колективно відповісти на кілька найпоширеніших коментарів і критики:
-
«PoC не виконує payload»
Вірно. Мій proof-of-concept мав на меті лише продемонструвати механізм — як модель машинного навчання може виступати як архів/пакувальник і як навмисне перенавчання може кодувати ваги для «збереження» вихідного файлу.
Саме тому на GitHub ви не знайдете справжнього шкідливого коду або динамічного завантаження коду в пам’ять. Це було свідоме рішення — я хотів залишитись у межах чистого прототипу, а не створювати готовий інструмент для шкідливих цілей.
Репозиторій містить базовий приклад з класичним сортуванням бульбашкою, і нічого більше.
-
«Це просто витончена обфускація коду»
Згоден — у певному сенсі це так. Це нетрадиційна форма обфускації коду. Але цей «витончений» підхід відкриває нові вектори атаки:
- Немає бінарного файлу — код знаходиться в моделі, тож неможливо провести статичний аналіз.
- Відсутність традиційного розгортання — payload можна «витягти» лише за допомогою конкретної моделі та архітектури.
- Інференція як виявлення середовища — пісочниці часто вимикаються в режимі бездіяльності. Інференція виглядає для них як бенчмарк.
Більше того, якщо поєднати це з нативними системними API для виконання моделей (наприклад, Windows ML API, CoreML, DirectML), додати перестановку ваг і інші трюки — можна створити шкідливе ПЗ, яке є:
- статично невиявленим (бо немає що аналізувати),
- динамічно невидимим (бо виконується лише на фізичному апаратному забезпеченні: NPU/GPU),
- майже не відрізняється від легітимної ML-інференції.
Що далі?
Я вже працюю над кількома новими проєктами, які, сподіваюсь, також зацікавлять спільноту. Останній з них — кастомна клієнтська бібліотека для Model Context Protocol (MCP), створена бути легкою, функціональною і швидкою. Вона покликана усунути недоліки існуючих рішень, які не мають усіх цих якостей. Деталі з’являться найближчим часом у наступній статті.
Ще раз дякую всім за коментарі, натхнення і конструктивну критику. Якщо вам сподобався мій попередній допис, дайте знати — кожен відгук мотивує мене продовжувати дослідження.
Оновлення
2025-06-29 15:05 Я опублікував цю статтю на Reddit (r/MachineLearning), де вона отримала багато позитивних відгуків. Оригінальну тему можна знайти тут.
Від перекладача
Це переклад сразу двох статей, перша стаття це була головна ідея упаковки шкідливого коду у моделі, і далі відповіді на головні питання.