Вартість програмного забезпечення з відкритим кодом
Це переклад статті від Гарвадської школи бізнеса. Орігінал тут
Зміст
- Анотація
- 1. Вступ
- 2. Емпіричне налаштування та дані
- 3. Методика
- 4. Результати
- 5. Висновок
- Онлайн-додаток
Manuel Hoffmann
Harvard Business School
Frank Nagle
Harvard Business School
Yanuo Zhou
University of Toronto
Copyright © 2024 by Manuel Hoffmann, Frank Nagle, and Yanuo Zhou. Working papers are in draft form. This working paper is distributed for purposes of comment and discussion only. It may not be reproduced without permission of the copyright holder. Copies of working papers are available from the author. The authors are grateful for financial and administrative support from the Linux Foundation without which the data from the Census would not have otherwise been available. We greatly appreciate the support of the Research Computing Services at Harvard Business School, the Laboratory for Innovation Science at Harvard, the Linux Foundation, and the software composition analysis data providers Snyk, the Synopsys Cybersecurity Research Center, and FOSSA. We thank Tianli Li and Misha Bouzinier for excellent research assistance. We are also thankful to the software developer Boris Martinovic as well as Rich Lander and Scott Hanselman from Microsoft for insights into the .NET ecosystem. We received helpful feedback from participants at the Harvard Business School Values and Valuations Conference, the Harvard Business School D3 Research Day, and the 2023 Academy of Management Conference. Funding for this research was provided in part by Harvard Business School.
Вартість програмного забезпечення з відкритим кодом
Manuel Hoffmanna Frank Nagle b Yanuo Zhouc This version: January 1, 2024
Анотація
Вартість негрошового (безкоштовного) продукту за своєю суттю важко оцінити. Поширеним прикладом є програмне забезпечення з відкритим кодом (ВВК), глобальне суспільне благо, яке відіграє життєво важливу роль в економіці та є основою для більшості технологій, які ми використовуємо сьогодні. Однак важко виміряти цінність ВВК через його негрошовий характер і відсутність централізованого відстеження використання. Таким чином, ВВК залишається значною мірою неврахованим в економічних показниках. Незважаючи на те, що попередні дослідження оцінювали витрати з боку пропозиції на відтворення цього програмного забезпечення, брак даних заважав оцінити набагато більшу цінність на стороні попиту (користування), яку створює ВВК. Тому, щоб зрозуміти повну економічну та соціальну цінність широко використовуваного ВВК, ми використовуємо унікальні глобальні дані з двох додаткових джерел, які фіксують використання ВВК мільйонами глобальних компаній. Спочатку ми оцінюємо цінність з боку пропозиції, підраховуючи вартість одноразового відтворення найпоширенішого ВВК. Потім ми розраховуємо вартість на стороні попиту на основі вартості заміни для кожної фірми, яка використовує програмне забезпечення та потребувала б створити його всередині компанії, якби ВВК не існувало. За нашими оцінками, вартість широко використовуваних ВВК на стороні пропозиції становить 4,15 мільярда доларів, але вартість на стороні попиту набагато вища – 8,8 трильйона доларів. Ми виявили, що компаніям довелося б витрачати в 3,5 рази більше на програмне забезпечення, ніж зараз, якби ВВК не існувало. Шість найкращих мов програмування в нашій вибірці становлять 84% цінності ВВК з боку попиту. Крім того, 96% цінності з боку попиту створюють лише 5% розробників ВВК.
JEL Classification: H4; O3; J Keywords: Open-source software, global public good
Acknowledgement: The authors are grateful for financial and administrative support from the Linux Foundation without which the data from the Census would not have otherwise been available. We greatly appreciate the support of the Research Computing Services at Harvard Business School, the Laboratory for Innovation Science at Harvard, the Linux Foundation, and the software composition analysis data providers Snyk, the Synopsys Cybersecurity Research Center, and FOSSA. We thank Tianli Li and Misha Bouzinier for excellent research assistance. We are also thankful to the software developer Boris Martinovic as well as Rich Lander and Scott Hanselman from Microsoft for insights into the .NET ecosystem. We received helpful feedback from participants at the Harvard Business School Values and Valuations Conference, the Harvard Business School D^3 Research Day, and the 2023 Academy of Management Conference.
M5S 3E6, Canada, E-Mail: yanuo.zhou@rotman.utoronto.ca.
1. Вступ
У 2011 році венчурний капіталіст Марк Андріссен (Mark Andreessen) висловив знамениту думку про те, що «програмне забезпечення поїдає світ» (Andreessen, 2011), сьогодні мало хто сперечатиметься з цим. Нещодавно венчурний капіталіст Джозеф Джекс(Joseph Jacks) стверджував, що «відкрите програмне забезпечення з’їдає програмне забезпечення швидше, ніж програмне забезпечення з’їдає світ» (Jacks, 2022). Інші останні дослідження дійшли подібних висновків, показуючи, що програмне забезпечення з відкритим кодом (ВВК) – програмне забезпечення, вихідний код якого є загальнодоступним для перевірки, використання та модифікації та часто створюється децентралізованим способом і поширюється безкоштовно – з’являється в 96% кодових баз. (Synopsys 2023) і що деяке комерційне програмне забезпечення на 99,9% складається з вільно доступних ВВК (Musseau та ін., 2022). Хоча на початку свого існування ВВК часто копіював функції з існуючого пропрієтарного програмного забезпечення, сьогодні ВВК включає передові технології в різних сферах, включаючи штучний інтелект (AI), квантові обчислення, великі дані та аналітику. Однак, незважаючи на зростаючу важливість ВВК для всього програмного забезпечення (і, отже, для всієї економіки), виміряти його вплив було важко. Традиційно, щоб виміряти вартість, створену товаром або послугою, економісти множать ціну (p) на продану кількість (q). Проте в ВВК p зазвичай дорівнює нулю, оскільки вихідний код є загальнодоступним, а q невідомий через обмежену кількість обмежень щодо того, як код можна копіювати та повторно використовувати. Наприклад, якщо компанія завантажує частину ВВК із загальнодоступного репозіторія коду, вона може скопіювати її тисячі разів всередину (на законних підставах), а потім поділитися з постачальниками чи клієнтами (також на законних підставах), тому загальнодоступних даних для завантаження недостатньо. Незважаючи на те, що деякі нещодавні дослідження намагалися оцінити значення p (обговорюється нижче), дані для оцінки q були недоступні або важкооброблені для чогось іншого, ніж просто для кількох пакетів ВВК. Використовуючи нещодавно зібрані дані з багатьох джерел, мета цієї статті — надати оцінки як для p, так і для q та використати їх, щоб прояснити питання: яка цінність програмного забезпечення з відкритим кодом?
Розуміння цінності ВВК має вирішальне значення не лише через роль, яку вона відіграє в економіці, але й через те, що вона є одним із найуспішніших і найвпливовіших сучасних прикладів багатовікової економічної концепції «загальних благ», яка має ризик зустріти долю, відому як «трагедія громад». Ця концепція сягає корінням ще в 4-е століття до нашої ери, філософ Аристотель, який писав: «Те, що є спільним для найбільшої кількості людей, потребує найменшої уваги. Люди найбільше звертають увагу на те, що є своїм, і менше піклуються про те, що є спільним». (Аристотель, 1981). Вільям Форстер Ллойд (1833) відновив цю ідею в сучасній економічній думці, навівши приклад спільних ділянок землі, які використовувалися для випасу худоби кількома пастухами, кожен з яких мав стимул надмірно використовувати спільний ресурс. Гаррет Гардін (1968) переніс цю концепцію в ширший дух часу, коли написав статтю, де обговорював проблему під назвою «Трагедія громад». Спираючись на цю роботу, Елінор Остром отримала Нобелівську премію за дослідження, що висвітлює шляхи уникнення трагедії громад шляхом координації зусиль громади, які не вимагають застосування державними законами для управління та охорони спільного надбання (Ostrom 1990). Паралелі між спільними пасовищами та спільною цифровою інфраструктурою є відчутними – доступність комунальної трави для годування худоби та, у свою чергу, годування людей, була критично важливою для аграрної економіки, а можливість не відтворювати код, який уже написав хтось інший, має вирішальне значення для сучасної економіки. Крім того, в обох контекстах, незважаючи на те, що знаємо, що трава і код є критично важливими факторами економіки, виміряти їх фактичну вартість важко. І, як вважається, сказав відомий математик і фізик лорд Кельвін: «Якщо ви не можете це виміряти, ви не можете це покращити». І якщо ви не можете покращити та підтримувати їх, такі загальні блага можуть розвалитися під вагою власного успіху, оскільки їх надмірно використовують, але в них недостатньо інвестують (Ліфшиц-Ассаф та Нейгл, 2021). Тому вимірювання цінності, яку створює ВВК, має вирішальне значення для майбутнього здоров’я цифрової економіки та решти економіки, яка побудована на ній.
Важливо те, що останні дослідження намагалися вирішити ці проблеми вимірювання, але не змогли охопити як широту, так і глибину використання ВВК – прогалину, яку ми прагнемо заповнити цією роботою. Наприклад, дослідники намагалися розширити масштаби, використовуючи нові методології, щоб оцінити вартість заміщення робочої сили поточного корпусу ВВК, створеного в Сполучених Штатах як 38 мільярдів доларів у 2019 році (Robbins et al., 2021), а також того, що було створено в Європейському Союзі. як 1 мільярд євро (Blind et al., 2021) шляхом врахування витрат на оплату праці, які були б потрібні для переписування існуючого ВВК. Такі зусилля дуже добре допомагають оцінити, скільки коштуватиме заміна всього існуючого ВВК, якщо вони зникнуть завтра. Однак отримані оцінки ґрунтуються на двох важливих припущеннях. По-перше, що весь ВВК є однаково цінними з точки зору використання, а по-друге, що концепція ВВК все ще існуватиме, і суспільству потрібно буде лише один раз переписати код, таким чином вирішуючи вищезгадану проблему відсутнього значення для p, але не вирішуючи відсутнє значення q. У світі, де ВВК взагалі не існувало, кожну частину програмного забезпечення ВВК не потрібно було б переписувати лише один раз, а натомість мала б бути переписана кожною фірмою, яка використовує програмне забезпечення (припускаючи, що фірма може вільно ділитися програмним забезпеченням у межах його межі). Інші дослідження (Greenstein and Nagle, 2014; Murciano-Goroff, Zhuo, and Greenstein, 2021) заглибилися в цю гіпотезу, хоча й у вузькій манері, зосередившись лише на веб-серверах (які є загальнодоступними в Інтернеті і тому можуть легко виміряти). Використовуючи різні методи, обидва дослідження вимірюють q для цього одного типу програмного забезпечення та приписують p за допомогою підходу відновної вартості товару на основі цін на альтернативи із закритим кодом, які пропонують фірми. З даними зі Сполучених Штатів отримані оцінки показують вартість ВВК Apache Web Server у 2 мільярди доларів у 2012 році (Greenstein and Nagle, 2014) і загальну вартість у 4,5 мільярда доларів США для Apache та ВВК веб-сервера nginx у 2018 році (Murciano-Goroff та ін., 2021). Однак, хоча веб-сервери є важливою частиною екосистеми ВВК, вони становлять невелику її частину. Ми прагнемо спиратися на важливий внесок, зроблений цими існуючими дослідженнями, намагаючись вийти як широко, так і глибоко, щоб створити більш повну міру цінності ВВК.
Щоб розглянути цінність ВВК як широко, так і глибоко, ми використовуємо дані з двох основних джерел, які дозволяють нам отримати уявлення про ВВК, що використовується в десятках тисяч компаній у всьому світі. Перший – це «Census II вільного програмного забезпечення з відкритим кодом – бібліотеки програм» (Nagle та ін., 2022). Проект Census II використовував партнерство з кількома фірмами, що займаються аналізом складу програмного забезпечення (SCA), щоб створити різноманітні списки найбільш широко використовуваних ВВК. SCA наймають для сканування кодових баз компанії, щоб переконатися, що вони не порушують жодних ліцензій ВВК, і, як побічний продукт, відстежують увесь код ВВК, який використовують їхні клієнти, і продукти, які вони створюють. Проект Census II зібрав дані з кількох SCA для створення набору даних про використання ВВК у десятках тисяч фірм на основі мільйонів точок даних (спостережень за використанням ВВК). Другим джерелом даних є набір даних BuiltWith, з якого ми використовуємо сканування майже дев’яти мільйонів веб-сайтів, щоб визначити основну технологію, що розгортається на цих веб-сайтах, включаючи бібліотеки ВВК. Дані BuiltWith використовувалися в багатьох академічних дослідженнях (DeStefano & Timmis 2023, Dushnitsky & Stroube 2021, Koning et al.. 2022), але, наскільки нам відомо, це перше дослідження, яке присвячене використанню ВВК. Дані Census II і дані BuiltWith доповнюють один одного, оскільки перший зосереджується на ВВК, вбудованому в програмне забезпечення, яке продає компанія, тоді як другий зосереджується на ВВК, вбудованому на веб-сайт компанії, таким чином зменшуючи ймовірність подвійного підрахунку спостережень у наборах даних. У сукупності ці два набори даних створюють найповніше вимірювання використання ВВК ( q ) на сьогодні. Крім того, зосереджуючись на ВВК, яка широко розгорнута та використовується компаніями, а не на розгляді всіх проектів, які існують у сховищі ВВК, ми вдосконалюємо методології попередніх досліджень, зменшуючи ймовірність помилки вимірювання, що виникає в результаті проектів, які публікуються як загальнодоступні ВВК, але фактично практично не використовуються. Неврахування цієї помилки вимірювання призведе до переоцінки фактичної вартості ВВК, оскільки проекти, які широко використовуються, оцінюватимуться так само, як проекти, які не використовуються взагалі.
Щоб оцінити p, ми дотримуємося літератури, розглянутої вище, і використовуємо вартість праці по заміні. По-перше, ми обчислюємо витрати на оплату праці окремої фірми, щоб відтворити даний пакет ВВК, вимірюючи кількість рядків коду в пакеті, а потім застосовуючи модель конструктивних витрат II (Boehm, 1984; Boehm et al., 2009). – також відомий як COCOMO II – щоб оцінити кількість людино-годин, які знадобляться для написання коду з нуля. Потім ми використовуємо глобальні дані про заробітну плату від Salary Expert, щоб отримати точну оцінку витрат на оплату праці, які б понесла фірма, якби цієї частини ВВК не існувало. Ці витрати можна поєднати зі значеннями q вище на рівні пакету ВВК, щоб оцінити загальну вартість усіх ВВК як з боку пропозиції, так і з боку попиту.
Ми знаходимо вартість у діапазоні від 1,22 мільярда до 6,22 мільярда доларів, якщо ми вирішили як суспільство відтворити увесь широко використовуваний ВВК зі сторони пропозиції. Проте врахування фактичного використання ВВК призводить до того, що вартість з боку попиту на порядки більша і коливається від $2,59 трлн до $13,18 трлн, якби кожна фірма, яка використовувала пакет ВВК, мала відтворити його з нуля (наприклад, концепції ВВК не існувало). Ми документуємо значну неоднорідність значення ВВК за мовою програмування, а також зусилль щодо внутрішнього та зовнішнього програмування. Крім того, ми знаходимо значну неоднорідність у внесках цінності програмістів, оскільки 5% програмістів відповідають за понад 90% цінності, створеної на стороні попиту та пропозиції. Дані, які ми використовуємо, є, мабуть, найповнішим джерелом даних для вимірювання цінності, створеної використанням компаніями ВВК на даний момент. Однак, як і для будь-якого проекту, докази не є повними, і ми стверджуємо, що недооцінюємо цінність, оскільки наші дані, наприклад, не включають операційні системи, які є значною мірою пропущеною категорією ВВК.
Це дослідження робить чотири важливі внески до наукової літератури, практиків і політиків. По-перше, воно надає найповнішу оцінку вартості широко використовуваних ВВК на сьогоднішній день, враховуючи не лише пропозицію ВВК (ціну на її створення), але й використання/попит у масштабі, який не було зроблено раніше. У той час як попередні оцінки цінності ВВК були лише широкими (оцінка витрат з боку пропозиції великої групи ВВК) або глибокими (оцінка вартості, створеної одним конкретним типом ВВК), це дослідження робить і те, і інше за допомогою унікальних наборів даних, які дозволяють краще зрозуміти широту та глибину використання ВВК. Крім того, замість того, щоб вимірювати цінність усіх ВВК, це дослідження зосереджено на цінності ВВК, яка використовується компаніями для створення своїх продуктів і веб-сайтів, обмежуючи похибку вимірювання, що виникає в дослідженнях, які не можуть пояснити, для яких ВВК насправді використовується в виробництві. Цей внесок спирається на важливі дослідження (наприклад, Blind та ін., 2021; Greenstein та Nagle, 2014; Murciano-Goroff та ін., 2021; Robbins та ін., 2021), які намагалися визначити цінність цього життєво важливого ресурсу, який робить великий внесок у сучасну економіку, незважаючи на труднощі у вимірювання цього внеску. Роблячи це, дослідження додає ідеї до тривалої дискусії, пов’язаної з впливом інформаційних технологій (ІТ) на продуктивність (Brynjolfsson, 1993; Brynjolfsson and Hitt, 1996; Nagle, 2019a; Solow, 1987), відомої як «парадокс продуктивності», де інвестиції в ІТ можуть мати обмежений вплив на статистику продуктивності. Ці дебати тривають у новому контексті ШІ (Brynjolfsson, Rock, and Syverson, 2018). Наша робота сприяє цій розмові, висвітлюючи значну економію коштів на суспільному рівні (і, отже, підвищення продуктивності), яку створює існування ВВК.
По-друге, наше дослідження вносить методологічний прогрес у вивчення нематеріального капіталу, висвітлюючи нові джерела даних, пов’язаних з інвестиціями в ВВК. Попередні дослідження показали, що нематеріальний капітал відіграє дедалі важливішу роль в економічному зростанні (Corrado, Hulten, and Sichel, 2009) і вартості фірми (Peters and Taylor, 2017), але його часто не вимірюють або неправильно розподіляють (Eisfeldt and Papanikolaou, 2014). Крім того, ми демонструємо, як ці джерела даних можна використовувати, щоб зрозуміти справжні інвестиції в програмне забезпечення, які робить фірма, і те, що вони повинні були б зробити, якби ВВК не існувало. Це важливо, оскільки інвестиції в програмне забезпечення стають дедалі важливішим типом нематеріального капіталу, який сприяє інноваціям (Branstetter, Drev, and Kwon, 2019) і продуктивності (Krishnan et al., 2000).
По-третє, наші результати допомагають підкреслити для компаній і менеджерів важливість ВВК для їхнього виробництва та в ідеалі додають ваги аргументам про те, що користувачі ВВК повинні не лише безкоштовно користуватися, але й робити свій внесок у створення та підтримку ВВК (наприклад, Henkel, 2008; Нейгл, 2018). Такі внески становлять незначну частину витрат, які б зазнали фірми, якби ВВК не існувало, і активна участь користувачів ВВК у підтримці ВВК, яку вони використовують, має вирішальне значення для здоров’я та майбутнього добробуту екосистеми ВВК (Ліфшиц-Ассаф і Nagle, 2021; Чжан та ін., 2019).
По-четверте, і нарешті, наше дослідження допомагає інформувати політиків, які нещодавно почали розуміти зростаючу важливість ВВК для економіки та вжили заходів для підтримки екосистеми (Європейська комісія, 2020; виконавчий наказ № 14028, 2021). Однак більшість цих зусиль пов’язані із забезпеченням безпеки існуючої екосистеми ВВК, що є досить важливим, але не доходить до підтримки створення нових ВВК. Наші результати допомагають пролити світло на важливість ВВК для загальної економіки та додати ваги закликам до більшої суспільної підтримки цього важливого ресурсу. Наші результати також показують, що більшість цінностей, створених ВВК, створюється невеликою кількістю учасників. Хоча вже давно відомо, що невелика кількість учасників ВВК виконує більшу частину роботи, ми додаємо нові відомості, які показують, що це ще більше стосується створення цінності широко використовуваних проектів ВВК і що суспільна підтримка цих осіб є критично важливою для майбутній успіху ВВК і, у свою чергу, економіки.
Інша частина цього документа організована таким чином. Розділ 2 описує емпіричне налаштування та дані. Розділ 3 обговорює методи, включаючи проблеми вимірювання. У розділі 4 ми оцінюємо цінність програмного забезпечення з відкритим кодом. Розділ 5 завершується.
2. Емпіричне налаштування та дані
Хоча концепція вільного та відкритого програмного забезпечення існує з 1950-х років, вона стала більш популярною у 1980-х роках завдяки зусиллям Річарда Столмана та його запуску проекту GNU та Фонду вільного програмного забезпечення (Maracke, 2019). Однак саме в 1990-х роках ВВК набула популярності після того, як Лінус Торвальдс випустив ядро Linux, широко поширену операційну систему ВВК (Tozzi, 2016). Сьогодні ВВК вважається ключовим будівельним блоком цифрової економіки та широко використовується розробниками програмного забезпечення в усьому: від телефонів до автомобілів, холодильників і передового штучного інтелекту (Lifshitz-Assaf and Nagle, 2021).
Ми використовуємо два основних джерела даних, які доповнюють один одного, щоб оцінити цінність ВВК. Перший – це Cesus, звернений всередину. Це дозволяє нам ідентифікувати код ВВК, який входить до продуктів, які створюють компанії. Другий набір даних — це BuiltWith і спрямований назовні, що дозволяє нам ідентифікувати код ВВК, з яким споживачі безпосередньо взаємодіють через веб-сайти фірм. Оскільки необроблені дані в обох наборах даних містять лише назви пакетів, номери версій та імена менеджерів пакетів і не містять жодної інформації, пов’язаної з вихідним кодом, ми спочатку отримуємо загальнодоступне сховище коду для кожного пакета, яке містить інформацію на рівні пакета, включаючи рядки коду та використовуваних мов програмування. Можна хвилюватися про подвійний підрахунок для розрахунків вартості в результаті використання двох окремих наборів даних. Однак перекриття вибірки Census і BuiltWith дуже невелике: в обох наборах даних знайдено лише 18 пакетів. Крім того, малоймовірно, що подвійний підрахунок викликає занепокоєння, оскільки два набори даних фіксують різні виміри використання ВВК: Census фіксує упаковане програмне забезпечення, використання якого спрямоване всередину, тоді як BuiltWith фіксує використання на веб-сайтах, які спрямовані назовні. Нарешті, як додатковий набір даних ми використовуємо GHTorrent, детальну історію діяльності, пов’язаної з ВВК, на GitHub, найпопулярнішій платформі розміщення ВВК і широко використовуваному джерелі даних для досліджень ВВК (наприклад, Burton et al, 2017; Conti, Peukert і Roche, 2023; Fackler, Hofmann і Laurentsyeva, 2023; Ці детальні історичні дані дозволяють нам глибше зрозуміти, як створюється цінність ВВК, завдяки кращому розумінню розподілу внесків між окремими розробниками ВВК. Нижче ми описуємо деталі всіх трьох джерел даних та їхню підготовку до оцінки.
Перепис. Другий перепис (Census II) вільного програмного забезпечення з відкритим кодом (тут: Перепис) спільно провели Linux Foundation і Лабораторія науки про інновації в Гарварді (Нагл та ін., 2022).1 Перепис було створено шляхом агрегування даних від трьох великих компаній з аналізу складу програмного забезпечення (SCA), які мають тисячі клієнтів по всьому світу. SCA наймають для сканування кодової бази клієнта та збору даних про використання ВВК, вбудованого в їхнє власне програмне забезпечення, щоб переконатися, що вони не порушують жодних ліцензійних угод ВВК.2 Часто це відбувається як частина процесу аудіту, пов’язаного зі злиттям і придбанням (merge and aсquistion). На відміну від інших вимірювань попиту на ВВК, доступних із загальнодоступних джерел, таких як підрахунок завантажень пакетів і зміни коду, спосіб збору цих даних гарантує, що ми спостерігаємо точну кількість і тип внутрішнього використання ВВК фірмами. Крім того, це дозволяє нам відстежувати залежності, на які покладається кожен пакет, щоб ми могли спостерігати непряме використання ВВК, яке зазвичай приховано та важко отримати.3 Результатом є понад 2,7 мільйона спостережень пакетів ВВК, які використовуються всередині продукти, створені фірмами-клієнтами SCA на 2020 календарний рік (з 1 січня по 31 грудня 2020 року).4
Проект Census стандартизував назви пакетів на основі системи імен libraries.io – широко використовуваного сайту, підтримуваного Tidelift, який упорядковує інформацію про понад вісім мільйонів пакетів з відкритим кодом. Перепис зосередився на 2000 найпопулярніших пакетів на основі даних про використання, повідомлених трьома найвідомішими постачальниками SCA, щоб визначити найпоширеніші ВВК, а не довгий хвіст розподілу використання. Це призвело до того, що пакети з менш ніж п’ятьма спостереженнями використання були видалені. Оскільки пакунки, написані на мові програмування JavaScript і зазвичай розміщені в Node Package Manager (NPM), зазвичай менші (менша кількість рядків коду), ніж пакунки на інших мовах, і тому часто мають більші показники використання (оскільки розробники повинні включити багато невеликих пакетів замість кількох великих пакетів), перепис окремо відібрав 1000 найпопулярніших пакетів NPM і 1000 найпопулярніших пакетів, які не є NPM.
Цей остаточний набір даних охоплює 70% загального використання ВВК, спостережуваного в необроблених даних перепису.5 Для кожного з цих 2000 пакетів ВВК у переписі ми визначили необроблений код, який підтримується на GitHub, найбільш поширеній платформі. для розміщення ВВК.6 Спочатку ми спробували отримати уніфікований покажчик ресурсів (URL) репозіторію GitHub для кожного пакета з libraries.io. Нам вдалося зіставити 1657 пакетів зі сховищами за допомогою цього початкового методу.7 Для URL-адрес без відповідного репозіторію ми здійснили пошук Google, дотримуючись методу Сінгха (2020). Зокрема, для кожного невідповідного пакета ми використовували Google API для пошуку назви пакета та «Сховища GitHub» і розглядали першу URL-адресу репозіторію GitHub у результатах як найкращу відповідну URL-адресу GitHub.8 Це призвело до додаткового 174 пакунки підійшли до репозиторію. Нарешті, ми вручну шукали URL-адреси для решти 169 пакетів, щоб визначити відповідне сховище. Весь цей процес призвів до зіставлення 1840 із 2000 пакетів Census до репозіторію коду з необробленим вихідним кодом для пакета. Було визначено, що невідповідні пакети були або видалені з GitHub, або стали власністю (і тому оригінальний вихідний код більше не був доступний), і, отже, ручний пошук дозволив нам видалити ці 160 невідповідних пакетів (менше 8% вибірки перепису). 2000) з високою достовірністю згідно з нашим аналізом.
BuiltWith. Дані BuiltWith містять сканування всіх загальнодоступних веб-сайтів у всьому світі та ідентифікують технології, які вони використовують. На відміну від даних перепису, спрямованих усередину, які зосереджені на використанні ВВК, сканування даних BuiltWith для використання як пропрієтарних, так і ВВК на веб-сайтах фірм без чіткої диференціації. Щоб відокремити ВВК від пропрієтарного програмного забезпечення в BuiltWith, ми звернемося до підмножини всього програмного забезпечення веб-розробки з відкритим кодом у категорії технологій, яка включає «JavaScript та його бібліотеки», яка генерує 778 спостережень, що відповідають категорії NPM ВВК у даних перепису. Є дві причини для такого вибору вибірки. По-перше, ця дана категорія створена BuiltWith, і ми використовуємо її як проксі для ВВК, щоб відокремити її від грошового програмного забезпечення. По-друге, JavaScript, одна з основних технологій для створення веб-сайтів, є найпопулярнішою мовою програмування використовуємою на GitHub (GitHub, 2022) і, таким чином, дозволяє нам охопити найважливіші ВВК з точки зору попиту. Сканування охоплює 8,8 мільйона унікальних веб-сайтів і 72,8 мільйона відповідних спостережень за використанням ВВК з 1 січня по 16 листопада 2020 року. Крім того, щоб переконатися, що ми вимірюємо цінність використання ВВК у приватному секторі, ми зіставляємо прийнятні домени JavaScript ВВК від BuiltWith із веб-сайтами компаній, записаними в Orbis, Compustat і PitchBook, трьох широко використовуваних базах даних корпоративної діяльності, які фіксують зареєстровані підприємства по всьому світу. Виконання цього збігу гарантує, що ВВК, який використовується некомерційними веб-сайтами (наприклад, особистим веб-сайтом окремої особи), буде виключено з нашого аналізу. Це призводить до рівня відповідності 38,6%, що відповідає приблизно 3 мільйонам веб-сайтів різних фірм.
Для даних BuiltWith ми не можемо застосувати перший метод, який використовуємо для перепису (використовуючи libraries.io для визначення URL-адреси сховища), оскільки BuiltWith надав лише назви технологій, пов’язані з пакетами, та іншу інформацію (наприклад, пакет і імена менеджерів пакунків) не включено.9 Отже, ми починаємо з виконання методу пошуку Google, згаданого вище, який призводить до відповідності 695 пакунків репозиторіям. Потім ми вручну здійснили пошук за URL-адресами Github для 83 із решти невідповідних пакетів, у результаті чого додано 46 пакетів. Загалом для даних BuiltWith ми змогли ідентифікувати 741 із 778 збігів пакетів із сховищами. Як і дані перепису, решта 37 невідповідних пакетів (менше 5%) виключено з нашого аналізу, оскільки їх було видалено з GitHub.
База даних GHTorrent. Щоб отримати вимірювання дисперсії створення цінності ВВК, ми використовуємо базу даних GHTorrent, яка містить всю історію активності на GitHub за допомогою інтерфейсу прикладного програмування (API) GitHub Representational State Transfer (REST). Щоб оцінити внесок кожного розробника, ми використали його записи про репозиторії GitHub, комісії на рівні розробника та інформацію про загальнодоступний профіль розробника. Ми звузили вибірку для нашого аналізу внеску розробників у два етапи. По-перше, ми відвіяли репозиторії GitHub та їхні коміти з GHTorrent на основі URL-адрес сховища нашого спільного зразка Census-BuiltWith.10 По-друге, ми зосереджуємося на людському внеску в ВВК, видаливши приблизно вісім тисяч (12%) учасників GitHub, які ми вважали роботами.11 Остаточна вибірка містить близько шістдесяти тисяч розробників і 2,3 мільйона комітів.
Щоб підготувати ці три набори даних для оцінки, ми спочатку визначили кількість рядків коду та мови програмування, які використовуються для кожного пакета, використовуючи пакети ВВК pygount (для підрахунку кількості рядків коду) та linguist (для визначення мов програмування).[ ^12] Ми класифікуємо кожну окрему мову в одну з трьох різних груп, переходячи від більш ймовірно написаної людиною до більш імовірно написаної машиною (див. таблицю A1). Відро 1 містить мови програмування та мови розмітки (які, швидше за все, написані людиною), сегмент 3 містить дані (швидше за все, написані машиною), а сегмент 2 містить щось середнє, наприклад файли конфігурації та пакетну обробку (що інколи написані людиною, а інколи — машиною, але це важко визначити, лише дивлячись на код).12 Для нашої первинної оцінки ми використовуємо лише сегмент 1, забезпечуючи перевірку надійності сегментів 2 і 3 у Додаток, і, таким чином, наші результати представляють нижню межу. Нарешті, для деяких аналізів ми копаємо глибше та показуємо 5 найкращих мов програмування (за класифікацією GitHub, 2022 рік за 2020 рік; рік, з якого взято наші дані). До 5 найкращих мов програмування входять C (включаючи C# і C++), Java, JavaScript, Python і Typescript. Ми також додаємо Go до цього списку найпопулярніших мов, оскільки вона стає все більш широко використовуваною мовою в ВВК.
3. Методика
Спочатку ми вимірюємо цінність ВВК, розглядаючи пропозицію та попит на ВВК, використовуючи підхід до ринку праці.13 Уявний експеримент полягає в тому, що ми живемо у світі, де ВВК не існує, і його потрібно відтворювати на кожній фірмі. який використовує дану частину ВВК. Використовуючи підхід ринку праці, ми розраховуємо вартість заміщення робочої сили кожного пакета ВВК. Щоб оцінити вартість кожного пакету, ми використовуємо COCOMO II (Boehm, 1984; Boehm та ін., 2009) на рівні окремого пакета, а потім підсумовуємо всі значення пакету, щоб отримати вартість заміщення ринку праці з боку пропозиції. Потім ми масштабуємо значення з боку пропозиції на кількість разів, коли фірми використовують кожен пакет, при цьому усуваючи багаторазове використання всередині кожної фірми, щоб отримати значення з боку попиту.
По-друге, ми виходимо за межі сукупності та перевіряємо нерівність у процесі створення вартості. В ВВК, як і в багатьох творчих починаннях, зазвичай невелика група людей робить основну частину внесків, тоді як багато інших роблять невеликі внески (іноді це називається правилом 80/20, тобто 80% роботи зроблено) на 20% людей). Дослідження показали, що ці постійні учасники часто досягають впливових позицій у спільнотах ВВК завдяки їхнім зусиллям (Hanisch та ін., 2018). Тому, щоб краще зрозуміти дисперсію створення цінності серед розробників, ми спершу використовуємо дані GHTorrent і визначаємо внески окремих розробників двома способами: а) через їхні внески цінності ВВК безпосередньо та б) через загальну кількість сховищ, до яких вони зробили внесок. Потім ми перевіряємо, наскільки сконцентровані ці два показники внеску, щоб краще зрозуміти, багато чи мало розробників роблять внесок у загальну цінність, яку ми вимірюємо. Нижче ми пояснюємо точні деталі підходу до ринку праці та нерівності оцінок.
3.1 Підхід до ринку праці Для підходу ринку праці ми оцінюємо вартість ВВК шляхом розрахунку відновної вартості пакета. Ми запитуємо, скільки коштуватиме відтворення пакета, найнявши програміста та заплативши йому конкурентоспроможну ринкову зарплату. Щоб оцінити це значення на стороні постачання ($V_{S}^{Labor}$), ми беремо повний список пакетів ВВК, розглянутий вище, а потім підраховуємо рядки коду в кожному унікальному пакеті.14 Для кожного унікального пакета, i, ми обчислюємо значення, а потім підсумовуємо всі ці значення, щоб отримати загальне значення:
\[𝑉_{S}^{Labor}=\sum_{i=1}^{N}V_{S_i}=\sum_{i=1}^{N}P_i * 1 (1)\]У цьому розрахунку ми неявно не враховуємо жодних виробничих зовнішніх ефектів, оскільки ми припускаємо, що немає переливу знань від одного пакета до іншого, який би знизив вартість програмування.15 Ця методологія подібна до тієї, що використовується в інших роботах, які оцінити витрати з боку пропозиції ВВК (Blind et al., 2021; Nagle, 2019b; Robbins et al., 2021). Потім ми обчислюємо значення ВВК з боку попиту, додаючи інформацію про використання (Q) для кожного пакета:
\[𝑉_{D}^{Labor}=\sum_{i=1}^{N}V_{D_i}=\sum_{i=1}^{N}P_i * Q_i (2)\]Тут ми не враховуємо зовнішні ефекти споживання, тобто ми не допускаємо отримання вигоди для широкої громадськості, коли пакет було створено, і ми також гарантуємо, що кожна фірма замінює пакет, який вони використовують лише один раз, оскільки замінений пакет може бути використаний у фірмі як клубний товар (наприклад, див. Cornes and Sandler, 1996). Значення $𝑉_{S}^{Labor}$ відображає вартість одноразового перепису всіх широко використовуваних ВВК (наприклад, концепція ВВК все ще існує, але всі ці пакунки потрібно було переписати з нуля), тоді як значення $𝑉_{D}^{Labor}$ відображає вартість кожної фірми, яка використовує один із цих пакетів ВВК, щоб заплатити розробнику за переписування цих пакетів (наприклад, сама ВВК більше не існує).
Як для моделі пропозиції, так і для моделі попиту ми отримуємо доларову вартість для кожного пакета ($P_i$) за допомогою Constructive Cost Model II, також скорочено COCOMO II (Boehm 1984, Boehm et al. 2009). Ця модель раніше використовувалася Міністерством оборони Сполучених Штатів для оцінки вартості програмного проекту, а також у попередніх дослідженнях оцінки вартості ВВК (Blind et al., 2021; Nagle, 2019b; Robbins et al., 2021). Це дуже гнучка модель, яка дозволяє нам створювати нелінійні перетворення рядків коду в доларові значення. Він використовує наступне рівняння моделювання:
\[E_i=\alpha\eta L_i^{\beta} (3)\]де 𝐿 представляє рядки кодів у тисячах, а E – зусилля в одиницях людино-місяць для кожного проекту i. Відповідно до Blind et al. (2021), ми використовуємо значення параметрів за замовчуванням для 𝛼, 𝛽 та 𝜂. Параметри 𝛼, 𝛽 є нелінійними коригуючими коефіцієнтами, встановленими на 2,94 і 1,0997 відповідно. Параметр 𝜂 — це коефіцієнт коригування зусиль, який можна змінити, щоб включити суб’єктивні оцінки атрибутів продукту, обладнання, персоналу та проекту. Оскільки ми не маємо попереднього значення для кожного проекту, ми встановлюємо 𝜂 значення за замовчуванням одиниці. Щоб отримати ціну (𝑃() кожного проекту ВВК, ми потім помножимо результати рівняння (3) на зважену глобальну заробітну плату, яку отримав би середній програміст на відкритому ринку. Щоб обчислити глобальну заробітну плату, ми включаємо місячну базову суму зарплати розробників програмного забезпечення від Salary Expert для 30 найкращих країн за кількістю розробників GitHub у 2021 році (Wachs та ін., 2022).16 Вага кожної країни — це частка активних учасників GitHub у загальній кількості учасників. у 30 найкращих країнах ми також створюємо межі, використовуючи ринок праці з низькою (Індія) і високою (США), щоб краще зрозуміти, як вартість буде змінюватися залежно від групи програмістів, які використовуються для відтворення всіх ВВК. .17
3.2 Вимірювання внеску Щоб краще зрозуміти, як створюється цінність і однаково чи нерівномірно вона створюється, ми створюємо графічне зображення в три кроки. На першому кроці ми вимірюємо цінний внесок розробників. На другому кроці ми отримуємо показник кількості репозиторіїв, до яких вносяться розробники. Нарешті, ми надаємо графічне представлення обох, використовуючи загальновідому концепцію кривої Лоренца, щоб краще зрозуміти ступінь нерівності у внесках. Ми описуємо деталі нижче.
Внесок вартості. Ми розрахували значення попиту та пропозиції ВВК, які вніс кожен розробник. На рівні сховища ми кількісно оцінили пропорційний внесок кожного розробника в роботу, підрахувавши їхню частку комітів до загальної кількості комітів для репозиторію. Згодом ця частка була помножена окремо на величину попиту та пропозиції сховища, щоб отримати доданий внесок цього окремого учасника в сховище. Нарешті, ми об’єднуємо цінні внески в усіх сховищах для кожного розробника. Індивідуальний цінний внесок унікального розробника Dev, $V_j^{Dev}$, можна виразити так:
\[V_j^{Dev}=\sum_{j}^{N}\sigma_i^{Dev}*V_{ij} (7)\]де $\sigma_i^{Dev}$ — це частка комітів, зроблених головним розробником у сховищі i, а $V_{ij}$ — це значення попиту чи пропозиції для всього сховища i, указане в рівняннях (1) і (2), де 𝑗∈{𝐷,𝑆}, а N — це кількість сховищ у нашій основній вибірці, тобто Census і BuiltWith разом.
Внесок у репозіторій. Це просто кількість сховищ, до яких вносить певний розробник, і вона виражається таким чином:
\[N^{Dev}=\sum_{j}^{N}𝟙\{\sigma_i^{Dev} > 0\} (8)\]де 𝟙 — функція індикатора, що дорівнює 1, коли розробник має ненульову кількість комітів до репозиторію i. Цей захід передбачає різноманітні потреби ВВК, які вирішуються окремими розробниками. Разом із мірою внеску цінності вони допомагають нам зрозуміти, чи зосереджена загальна цінність у невеликій кількості розробників. Загалом для всієї екосистеми ВВК та її різноманітності може бути більш бажаним, якщо окремі розробники беруть участь у багатьох сховищах, а не лише в кількох.
Вимірювання дисперсії внесків. Щоб графічно дослідити дисперсію значень внесків розробників, ми використали криві Лоренца (Лоренц, 1905) щодо значень як попиту, так і пропозиції. Криві Лоренца є усталеним способом представлення нерівності, і, таким чином, вони дозволяють нам краще зрозуміти, наскільки розпорошені внески розробників у ВВК у приватній економіці. Розробники систематично розташовані в порядку зростання на основі їхнього внеску в попит і пропозицію ВВК, як показано в рівнянні (7). Згодом ці ранги були нормалізовані до шкали від 0 до 100 процентилів, що слугує значенням осі абсцис для кривих Лоренца. З іншого боку, вісь ординат представляє відповідні внески вартості $\sigma_i^{Dev}$. Графічне представлення в розділі результатів прояснить ступінь нерівності, що стосується внесків вартості між розробниками. Щоб доповнити аналіз, ми додатково дослідили, наскільки розпорошений внесок сховища, $N^{Dev}$, побудувавши рівняння (8). Це дає нам змогу з’ясувати, чи є будь-яка істотна нерівність цінностей пов’язана з тим, що провідні учасники переважно зосереджуються на вузькій підмножині виключно популярних сховищ, чи, навпаки, з їхньої взаємодії з більш широким спектром успішних сховищ.
4. Результати
Після застосування підходу ринку праці з використанням COCOMO II ми отримуємо глобальні оцінки вартості ВВК. Щоб обчислити загальну цінність, нам спочатку потрібна базова кількість рядків коду (щоб обчислити значення з боку пропозиції), а потім статистика використання (для значення з боку попиту). Оскільки мовами програмування можуть бути суттєві неоднорідні значення, ми також показуємо найпопулярніші мови програмування протягом нашого досліджуваного періоду в 2020 році, як обговорювалося вище.
— Таблиця 1 приблизно тут —
Таблиця 1 показує описову статистику з обох наборів даних окремо. Внутрішній перепис (панель A) містить трохи більше 261,7 мільйона рядків коду, причому 72 % рядків припадають на найпопулярніші мови програмування. Середній пакет включає 142 тисячі рядків коду з дещо нижчим середнім показником 113 тисяч рядків коду для підмножини найкращих мов. Розглядаючи сторону попиту (використання), ми помічаємо, що пакети Census використовувалися понад 2,7 мільйона разів, при цьому 92 % цього використання припадає на найпопулярніші мови. Середній пакет використовувався 1472,4 рази з вищим використанням приблизно 1497,5 для найпопулярніших мов. Для зовнішніх даних BuiltWith ми знаходимо схожі шаблони, але на різних рівнях. Пакети, включені в BuiltWith, містять понад 82 мільйони рядків коду, 71% з яких відноситься до найкращих мов програмування. Середній пакет у зразку BuiltWith містить 111 тисяч рядків коду з нижчим середнім показником приблизно 80 тисяч рядків коду для найпопулярніших мов. Це пояснюється тим, що наші дані BuiltWith переважно складаються з пакетів на основі JavaScript, які часто менші за пакети, написані іншими мовами. Пакети BuiltWith використовувалися понад 142 тисячі разів, причому 99,97% припадає на найкращі мови. Далі ми використали ці необроблені спостереження, щоб обчислити вартість усіх ВВК за допомогою підходу ринку праці та оцінили вартість, створену з боку пропозиції та попиту.
— Таблиця 2 приблизно тут —
У таблиці 2 наведено оцінки вартості ВВК на основі спільної вибірки Census і BuiltWith, що стосується фірми. Усі оцінки в таблиці 2 базуються лише на мовах програмного забезпечення, класифікованих у сегменті 1 таблиці A1, які, швидше за все, будуть написані людиною, а не машиною.18 Перший стовпець містить оцінки із заробітною платою з низького доходу. країна (Індія), середня заробітна плата в світі та країна з високим доходом (Сполучені Штати Америки), відповідно (як описано вище). Щоб одноразово відтворити всі широко використовувані ВВК (наприклад, ідея ВВК все ще існує, але всі поточні ВВК видалені та потребують кодування з нуля), використовуючи програмістів із середньою заробітною платою розробника з Індії, знадобляться інвестиції $1,22 мільярда. Навпаки, якщо ми використовуємо середню зарплату розробника зі Сполучених Штатів, то відтворення всіх широко використовуваних ВВК потребуватиме інвестицій у розмірі 6,22 мільярда доларів. Використання пулу програмістів з усього світу, зважених на основі існуючих географічних внесків у ВВК, як обговорювалося вище, призвело б до інвестицій десь між країнами з низьким і високим рівнем доходу, $4,15 млрд. Корисно порівняти ці цифри з показниками подібних досліджень, щоб зрозуміти різницю в оцінці всіх ВВК (попередніх досліджень) і тих, які широко використовуються (наше дослідження). Роббінс та ін. (2021) і Блінд та ін. (2021) використали метод, схожий на наш, і оцінили, що вартість ВВК, створеного в США, становить 38 мільярдів доларів у 2019 році, а в ЄС – 1 мільярд євро у 2018 році. Wachs et al. (2022) показують, що приблизно 50% внесків ВВК надходять із США та ЄС разом. У сукупності це призведе до того, що ці дослідження дадуть глобальну вартість ВВК у 78 мільярдів доларів. Таким чином, наша середня оцінка вартості з боку пропозиції в 4,15 мільярда доларів лише для орієнтованих на фірму та широко використовуваних ВВК є надійною нижньою межею та підкреслює вищі оцінки загальної вартості з боку пропозиції ВВК, якщо не враховувати, чи чи не даний пакет ВВК широко використовується. Це додатково вказує на те, що значення з боку пропозиції найбільш широко використовуваних ВВК становить приблизно 5,5% від значення з боку пропозиції всіх ВВК.
Другий стовпець таблиці 2 містить оцінки попиту на основі підходу ринку праці. Ми виявили, що якби компаніям довелося відтворити всі пакети ВВК, які вони використовували (наприклад, самого ВВК більше не існувало, і кожна фірма, яка використовувала пакет ВВК, мала б його відтворити), тоді загальні витрати становитимуть від $2,59 трлн до $13,18 трлн використання робочої сили лише з країни з низькою чи високою зарплатою відповідно. Група програмістів по всьому світу може відтворити всі ВВК, які широко використовуються, вартістю приблизно 8,80 трильйонів доларів. Інтерпретація цього числа трохи складніша, але все ж можлива. Згідно зі звітом Statista (2023), глобальний дохід від програмного забезпечення у 2020 році (тому ж році, що й наші дані) становив 531,7 мільярда доларів. Однак це потік, а не запас програмного забезпечення. Покладаючись на державні оцінки, згідно з якими програмне забезпечення повністю знецінюється протягом трьох років, ми можемо зробити зворотний розрахунок конверта та розглянути купівельну вартість повного запасу готового програмного забезпечення, використаного у 2020 році, як сукупність того, що було продано з 2018 по 2020 рік, що становить \ 1,54 трильйона доларів. Крім того, це лише витрати на готове програмне забезпечення та не включає програмне забезпечення, придбане на замовлення або розроблене власними силами. Тут найкращі оцінки інвестицій приватного сектору в програмне забезпечення в цілому походять із даних звіту про національний дохід і продукт США (NIPA 2023). У 2020 році дані національних рахунків показують, що в США приватні компанії витратили 479,2 мільярда доларів на програмне забезпечення, з яких 45% (215,5 мільярда доларів) було розфасовано. Якщо ми припустимо, що це постійне співвідношення для решти світу, то загальна сума, яку фірми витратили на програмне забезпечення, яке використовувалося в 2020 році, становила 3,4 трильйона доларів (= 1,54 трильйона доларів/0,45). Поєднуючи цю приблизну оцінку з оцінкою вартості ВВК з боку попиту на основі середньої глобальної заробітної плати ($8,8 трлн), це означає, що фірми витратили б $12,2 трлн (=$3,4 трлн + $8,8 трлн), або в три з половиною рази скільки вони зараз витрачають, якби їм потрібно було заплатити власним розробникам за написання ВВК, яким вони зараз користуються безкоштовно.
— Малюнок 1 приблизно тут —
На малюнку 1 показано неоднорідність значення ВВК для найпопулярніших мов програмування. На панелі A показано значення сторони постачання, а вартість праці відображається на вертикальній осі. Ми виявили, що пакети ВВК, створені в Go, мають найвищу цінність із вартістю 80 3 мільйони доларів, яку довелося б створювати з нуля, якби пакети ВВК не існували. Відразу за Go йдуть JavaScript і Java з $758 і $658 млн відповідно. Вартість C і Typescript становить 406 мільйонів доларів США та 317 мільйонів доларів відповідно, тоді як Python має найнижчу вартість серед найпопулярніших мов – близько 55 мільйонів доларів. JavaScript є не лише найпопулярнішою мовою на GitHub принаймні з 2014 року (GitHub, 2022), це також мова з одним із найвищих значень у наших даних. Навпаки, Python з часом ставав все більш популярним, піднявшись із четвертого місця на друге місце у 2020 році серед усіх пакетів ВВК на GitHub, тоді як він займає останнє місце серед наших найкращих мов.
Панель B показує значення з боку попиту для найпопулярніших мов програмування. Виходячи з цінності використання, Go більш ніж у чотири рази перевищує цінність наступної мови, JavaScript. Typescript (мова, яка розширює JavaScript) значно зросла, піднявшись з десятого місця в топ-10 мов у 2017 році до четвертого місця в 2020 році, що також відображено в наших даних: Typescript є третьою за значенням мовою з боку попиту. За цими двома веб-мовами йдуть C, а Java та Python – далеко позаду.
— Малюнок 2 приблизно тут —
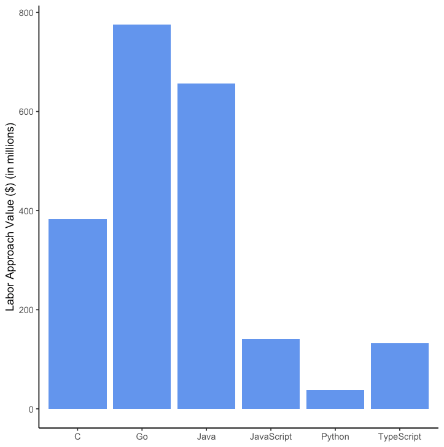
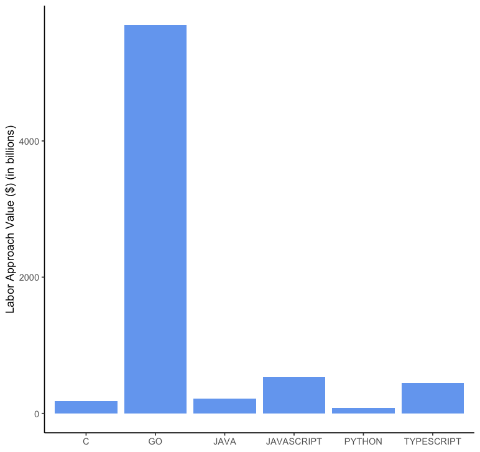
На малюнку 2 розділені оцінки значення ВВК для кожної мови за нашими внутрішніми (Census) і зовнішніми (BuiltWith) джерелами даних. Панелі A та B зосереджені на оцінці попиту та пропозиції для перепису. Ми отримуємо подібну модель, яка вже була встановлена в сукупності під час об’єднання обох джерел даних (рис. 1), хоча вплив JavaScript є значно меншим. На стороні пропозиції Перепису в панелі А Java має друге за величиною значення, тоді як код JavaScript з Перепису сприяє значно нижчому значенню в сукупності. Подібним чином значення C, Python і Typescript на стороні пропозиції в основному визначаються переписом. З боку панелі B з боку попиту ми виявили, що Go є найпопулярнішою мовою для внутрішнього коду, тоді як усі інші мови здаються незначними у відносному вираженні.
На рисунку 2, панель C і панель D показано значення попиту та пропозиції для набору даних BuiltWith. Значення сторони постачання на панелі C чітко вказує на те, що значення із зразка BuiltWith керується кодом JavaScript, що є хорошою перевіркою розумності, оскільки ми зосередилися на пакетах JavaScript для проксі для ВВК у зразку BuiltWith, як обговорювалося вище. Друге найвище значення створює TypeScript, що заспокоює, оскільки це надмножина JavaScript. Панель D демонструє подібну модель використання, де більша частина цінності виникає з JavaScript, тоді як TypeScript також відстає на другому місці. Інші мови вносять лише мізерні суми у значення попиту та пропозиції. Загалом ці висновки загалом узгоджуються з основними випадками використання різних мов (веб-програмування проти програмування додатків) та ідеєю, що мови, за допомогою яких генеруються цінності, не обов’язково ідентичні мовам, якими користується широка громадськість.
— Малюнок 3 приблизно тут —
На малюнку 3 показано значення попиту ВВК у галузях за 2-значними кодами NAICS з використанням онлайн-даних BuiltWith.19 Це можна інтерпретувати як значення, яке отримує кожна з цих галузей через існування ВВК. Галузь із найвищою вартістю використання — близько 43 мільярдів доларів — це «Професійні, наукові та технічні послуги». «Роздрібна торгівля», а також «Адміністративні та допоміжні послуги та послуги з управління відходами та відновлення» складають ще одну значну частину зовнішньої вартості ВВК з боку попиту з 36 і 35 мільярдами доларів США відповідно. Навпаки, галузі, які становлять лише невелику частину вартості, це «Гірнича промисловість, розробка кар’єрів, видобуток нафти та газу», «Комунальні послуги», «Сільське господарство, лісове господарство, рибальство та мисливство». Останні галузі є класичними галузями, не пов’язаними з обслуговуванням, і тому очікується, що програмне забезпечення відіграватиме там меншу роль.
— Малюнок 4 приблизно тут —
На малюнку 3 показано криві Лоренца та кількість сховищ, до яких долучилася частка програмістів для сторони пропозиції (панель A) і сторони попиту (панель B). Крива Лоренца, яка лежить прямо на лінії 45 градусів, означатиме дуже рівномірний розподіл значень між програмістами. Натомість панель A показує криву Лоренца як майже рівну лінію з різким збільшенням кінцевої частки програмістів. Це означає, що розподіл вартості пропозиції є дуже нерівномірним і значно більш концентрованим, ніж стандарт 80/20. Дійсно, останні п’ять відсотків програмістів, або 3000 програмістів, генерують понад 93% вартості з боку пропозиції. Подібним чином панель B показує – якщо врахувати використання – що останні п’ять відсотків створюють понад 96% вартості на стороні попиту. Загалом це вказує на те, що дуже невелика кількість програмістів створює основну частину коду ВВК, на який фірми сильно покладаються при створенні власного коду. Як на панелі A, так і на панелі B ми також бачимо збільшення кількості сховищ для останніх 10-15% програмістів, які роблять внесок у найвищу цінність, що означає, що нерівномірне значення, яке генерується декількома програмістами, є не просто до кількох дуже цінних сховищ, але завдяки внеску цієї жменьки учасників до значної кількості сховищ.
5. Висновок
У цьому дослідженні ми оцінюємо цінність широко використовуваного програмного забезпечення з відкритим кодом у всьому світі за допомогою двох унікальних наборів даних: даних Census of ВВК і даних BuiltWith. Ми можемо оцінити не лише цінність наявного коду з боку пропозиції (наприклад, вартість, яку знадобиться для переписування кожного фрагмента широко використовуваного ВВК), але й цінність з боку попиту для приватної економіки (наприклад, вартість взяти для кожної компанії, яка використовує частину ВВК, щоб переписати її). Хоча ми не зосереджуємося на довгому хвості ВВК, ми вважаємо це додатковим внеском нашого дослідження, оскільки зосередження на ВВК, яке широко використовується, дозволяє точніше зрозуміти цінність, яку створює ВВК, а не лише вимірювати вартість заміни для всіх ВВК (що переоцінило б справжнє значення, оскільки багато проектів ВВК не використовуються у робочому коді). Однак, незважаючи на те, що ми підкреслюємо значну цінність ВВК для нашого суспільства на основі широкого спектру даних про використання, неможливо ідентифікувати 100% ВВК, що використовується в усьому світі, тому наші оцінки з боку попиту, ймовірно, недооцінка справжньої вартості.
З поправкою на використання, ми знаходимо велике значення ВВК на стороні попиту в 8,8 трильйона доларів США, коли використовуємо програмістів з усього світу, з деякими відхиленнями, залежно від того, чи будемо ми наймати програмістів лише з країни з низьким чи високим рівнем доходу. Існує суттєва неоднорідність значення в мовах програмування та щодо того, чи є код внутрішнім – тобто для створення продуктів, які продаються – чи зовнішнім – тобто використовується на веб-сайті компанії. 6 найпопулярніших мов програмування створюють 84 % цінності з боку попиту. Ми також демонструємо значну неоднорідність за галузями промисловості та, нарешті, неоднорідність ціннісних внесків самих програмістів. Понад 95% вартості на стороні попиту генерується лише п’ятьма відсотками програмістів, і ці програмісти беруть участь не лише в кількох широко використовуваних проектах, а й у значно більшій кількості проектів, ніж програмісти, які працюють у нижньому кінці розподілу вартості. .
У сукупності наші результати показують значну цінність, яку ВВК робить для економіки, незважаючи на те, що це значення зазвичай дорівнює нулю шляхом прямого вимірювання, оскільки ціни дорівнюють нулю, а кількість важко виміряти, використовуючи лише публічні дані. Наше дослідження закладає основу для майбутніх досліджень не лише ВВК, але й усіх ІТ та їх зростаючого впливу на світову економіку.
Посилання
- Almeida, D. A., Murphy, G. C., Wilson, G., & Hoye, M. (2017, May). Do software developers understand open source licenses? In 2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC) (pp. 1-11). IEEE.
- Andreessen, M. (2011). Why Software Is Eating The World. Accessed May 1, 2023. Source: https://www.wsj.com/articles/SB10001424053111903480904576512250915629460
- Aristotle. (1981). Politics_._ Book 2, Chapter 3. T.A. Sinclair translation. Penguin Books, London.
- Blind, K., Böhm, M., Grzegorzewska, P., Katz, A., Muto, S., Pätsch, S., & Schubert, T. (2021). The impact of Open Source Software and Hardware on technological independence, competitiveness and innovation in the EU economy. European Commission, Ed.
- Blind, K., & Schubert, T. (2023). Estimating the GDP effect of Open Source Software and its complementarities with R&D and patents: evidence and policy implications. The Journal of Technology Transfer, 1-26.
- Boehm, B. W. (1984). Software engineering economics. IEEE transactions on Software Engineering, (1), 4-21.
- Boehm, B. W., Abts, C., Brown, A. W., Chulani, S., Clark, B. K., Horowitz, E., Madachy, R., Reifer, D., & Steece, B. (2009). Software cost estimation with COCOMO II. Prentice Hall Press.
- Branstetter, Lee G., Matej Drev, and Namho Kwon. (2019). “Get with the program: Software-driven innovation in traditional manufacturing.” Management Science 65, no. 2: 541-558.
- Brynjolfsson, E. (1993). The productivity paradox of information technology. Communications of the ACM, 36(12), 66-77.
- Brynjolfsson, E., & Hitt, L. (1996). Paradox lost? Firm-level evidence on the returns to information systems spending. Management Science, 42(4), 541-558.
- Brynjolfsson, E., Rock, D., & Syverson, C. (2018). Artificial intelligence and the modern productivity paradox: A clash of expectations and statistics. In The economics of artificial intelligence: An agenda (pp. 23-57). University of Chicago Press.
- Burton, R. M., Håkonsson, D. D., Nickerson, J., Puranam, P., Workiewicz, M., & Zenger, T. (2017). GitHub: exploring the space between boss-less and hierarchical forms of organizing. Journal of Organization Design , 6 , 1-19.
- Conti, A., Peukert, C., & Roche, M. (2023). “Beefing IT up for your Investor? Open Sourcing and Startup Funding: Evidence from GitHub.” Harvard Business School Working paper No. 22- 001.
- Cornes, R., & Sandler, T. (1996). The theory of externalities, public goods, and club goods. Cambridge University Press.
- DeStefano, T., and J. Timmis (2023). Demand Shocks and Data Analytics Diffusion, working paper.
- Dushnitsky, G., & Stroube, B. K. (2021). Low-code entrepreneurship: Shopify and the alternative path to growth. Journal of Business Venturing Insights, 16, e00251.
- Eisfeldt, A. L., & Papanikolaou, D. (2014). The value and ownership of intangible capital. American Economic Review, 104(5), 189-194.
- European Commission. (2020). Open Source Software Strategy 2020-2023. Luxembourg: Office for Official Publications of the European Communities.
- Executive Order No. 14028. (2021). Executive Order on Improving the Nation’s Cybersecurity. May 2021.
- Fackler, T., Hofmann, M., & Laurentsyeva, N. (2023). Defying Gravity: What Drives Productivity in Remote Teams? (No. 427). CRC TRR 190 Rationality and Competition.
- Greenstein, S., & Nagle, F. (2014). Digital dark matter and the economic contribution of Apache. Research Policy , 43 (4), 623-631.
- GitHub (2022). “Octoverse: The state of open source software.” Accessed November 3, 2023. https://octoverse.github.com/2022/top-programming-languages.
- Hanisch, M., Haeussler, C., Berreiter, S., & Apel, S. (2018, July). Developers’ progression from periphery to core in the Linux kernel development project. In Academy of Management Proceedings (Vol. 2018, No. 1, p. 14263). Briarcliff Manor, NY 10510: Academy of Management.
- Hardin, G. (1968). “The Tragedy of the Commons”. Science. 162 (3859): 1243–1248.
- Henkel, J. (2009). Champions of revealing—the role of open source developers in commercial firms. Industrial and Corporate Change, 18(3), 435-471.
- Jacks, J. (2022). Open Source Is Eating Software FASTER than Software Is Eating The World. Accessed May 1, 2023. Source: https://www.coss.community/cossc/open-source-is-eating-software-faster-than-software-is-eating-the-world-3b01
- Kim, D. Y. (2020). Product Market Performance and Openness: The Moderating Role of Customer Heterogeneity. In Academy of Management Proceedings (Vol. 2020, No. 1, p.21309). Briarcliff Manor, NY 10510: Academy of Management.
- Koning, R., Hasan, S., & Chatterji, A. (2022). Experimentation and start-up performance: Evidence from A/B testing. Management Science, 68(9), 6434-6453.
- Krishnan, M. S., Kriebel, C. H., Kekre, S., & Mukhopadhyay, T. (2000). An empirical analysis of productivity and quality in software products. Management science, 46(6), 745-759.
- Lerner, J., & Tirole, J. (2005). The scope of open source licensing. Journal of Law, Economics, and Organization, 21(1), 20-56.
- Lorenz, M. O. (1905). “Methods of measuring the concentration of wealth”. Publications of the American Statistical Association. Publications of the American Statistical Association , Vol. 9, No. 70. 9 (70): 209–219. Bibcode:1905PAmSA…9..209L. doi:10.2307/2276207. JSTOR 2276207.
- Lifshitz-Assaf, H., & Nagle, F. (2021). The digital economy runs on open source. Here’s how to protect it. Harvard Business Review Digital Articles. https://hbr.org/2021/09/the-digital-economy-runs-on-open-source-heres-how-to-protect-it.
- Lloyd, W. F. (1833). Two lectures on the checks to population: Delivered before the University of Oxford, in Michaelmas Term 1832. JH Parker.
- Maracke, C. (2019). Free and Open Source Software and FRAND‐based patent licenses: How to mediate between Standard Essential Patent and Free and Open Source Software. The Journal of World Intellectual Property, 22(3-4), 78-102.
- Murciano-Goroff, R., Zhuo, R., & Greenstein, S. (2021). Hidden software and veiled value creation: Illustrations from server software usage. Research Policy , 50 (9), 104333.
- Musseau, J., Meyers, J. S., Sieniawski, G. P., Thompson, C. A., & German, D. (2022, May). Is open source eating the world’s software? Measuring the proportion of open source in proprietary software using Java binaries. In Proceedings of the 19th International Conference on Mining Software Repositories (pp. 561-565).
- Nagle, F. (2018). Learning by contributing: Gaining competitive advantage through contribution to crowdsourced public goods. Organization Science, 29(4), 569-587.
- Nagle, F. (2019a). Open source software and firm productivity. Management Science, 65(3), 1191-1215.
- Nagle, Frank (2019b). “Government Technology Policy, Social Value, and National Competitiveness.” Harvard Business School Working Paper, No. 19-103, March 2019.
- Nagle, F., Dana, J., Hoffman, J., Randazzo, S., & Zhou, Y. (2022). Census II of Free and Open Source Software—Application Libraries. _Linux Foundation, Harvard Laboratory for Innovation Science (LISH) and Open Source Security Foundation (OpenSSF). https://www.linuxfoundation.org/research/census-ii-of-free-and-open-source-software-application-libraries.
- NIPA (2023). Bureau of Eonomic Analysis, NIPA Table 5.6.5. accessed: 2023- 11 - 14, source:https://apps.bea.gov/iTable/?reqid=19&step=3&isuri=1&select_all_years=0&nipa_table_list=331&series=q&first_year=2013&last_year=2023&scale=-9.
- Nordhaus, William D., 2006, “Principles of National Accounting for Nonmarket Accounts,” in _A
- New Architecture for the US National Accounts_ , editors, Dale W. Jorgenson, J. Steven Landefeld, and William D. Nordhaus, University of Chicago Press.
- Ostrom, Elinor (1990). Governing the commons: The evolution of institutions for collective action. Cambridge: Cambridge University Press.
- Peters, R. H., & Taylor, L. A. (2017). Intangible capital and the investment-q relation. Journal of Financial Economics, 123(2), 251-272.
- Robbins, C., Korkmaz, G., Guci, L., Calderón, J. B. S., & Kramer, B. (2021). A First Look at Open-Source Software Investment in the United States and in Other Countries, 2009-2019.
- Singh, Shivendu Pratap (2020) Products, Platforms, and Open Innovation: Three Essays on Technology Innovation. Doctoral Dissertation, University of Pittsburgh. (Unpublished)
- Solow, R. (1987). “We Better Watch Out.” New York Times Book Review , July 1987, p. 36.
- Statista (2023). Statista Software Worldwide, accessed 2023- 11 - 14, source: - https://www.statista.com/outlook/tmo/software/worldwide#revenue, accessed November 2023.
- Synopsys (2023). 2023 OSSRA: A deep dive into open source trends. Accessed May 1, 2023. Source : https://www.synopsys.com/blogs/software-security/open-source-trends-ossra-report/
- Tang, S., Wang, Z., & Tong, T. (2023). Knowledge Governance in Open Source Contributions: The Role of Gatekeepers. In Academy of Management Proceedings (Vol. 2023, No. 1, p.17622). Briarcliff Manor, NY 10510: Academy of Management.
- Tozzi, C. (2016). “Open Source History: Why Did Linux Succeed?” Channel Futures , August, 2016. Accessed November 3, 2023. https://www.channelfutures.com/open-source/open-source-history-why-did-linux-succeed
- Wachs, J., Nitecki, M., Schueller, W., & Polleres, A. (2022). The geography of open source software: Evidence from github. Technological Forecasting and Social Change , 176 , 121478.
- Williamson, S. (2006). Notes on macroeconomic theory. University in St. Louis. Department of Economics.
- Zhang, Y., Zhou, M., Mockus, A., & Jin, Z. (2019). Companies’ participation in oss development–an empirical study of openstack. IEEE Transactions on Software Engineering, 47(10), 2242 - 2259.
Малюнок 1 Цінність програмного забезпечення з відкритим кодом: найпопулярніші мови
Панель A. Сторона постачання
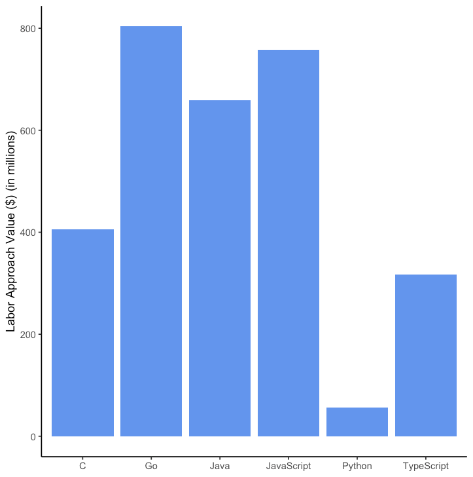
Панель B. Сторона попиту
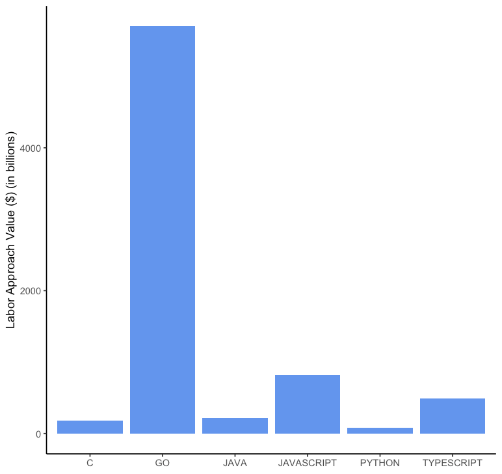
Примітка. Цифри показують вартість ринку праці для 5 найкращих мов за GitHub plus Go. На панелі A відображається сторона постачання, а на панелі B – використання. Що стосується праці, ми використовуємо нашу розрахункову середню глобальну заробітну плату для програмістів, як пояснюється в розділі методології.
Малюнок 2 Значення відкритого коду для 5 найкращих мов + Go та джерел даних
Панель А. Перепис. Сторона постачання
Панель Б. Перепис. Сторона попиту
Панель C. BuiltWith. Сторона постачання
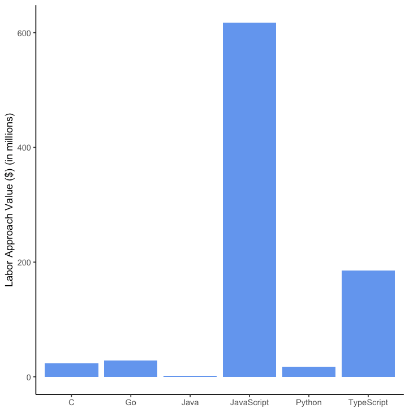
Панель D. BuiltWith. Сторона попиту
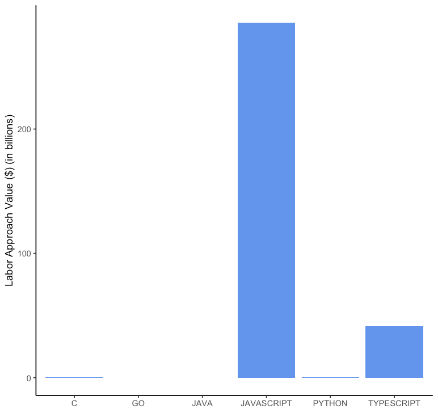
Примітка. Цифри показують ринкову вартість робочої сили та товарів для 5 найпопулярніших мов (згідно з GitHub) + Go, розділених за джерелами даних, спрямованими всередину (Census) і зовнішніми (BuiltWith). Панелі A та B показують значення з боку пропозиції та попиту для перепису, а панелі C та D — значення з боку пропозиції та попиту для BuiltWith.
Малюнок 3 Значення відкритого коду в різних галузях із веб-сайтів
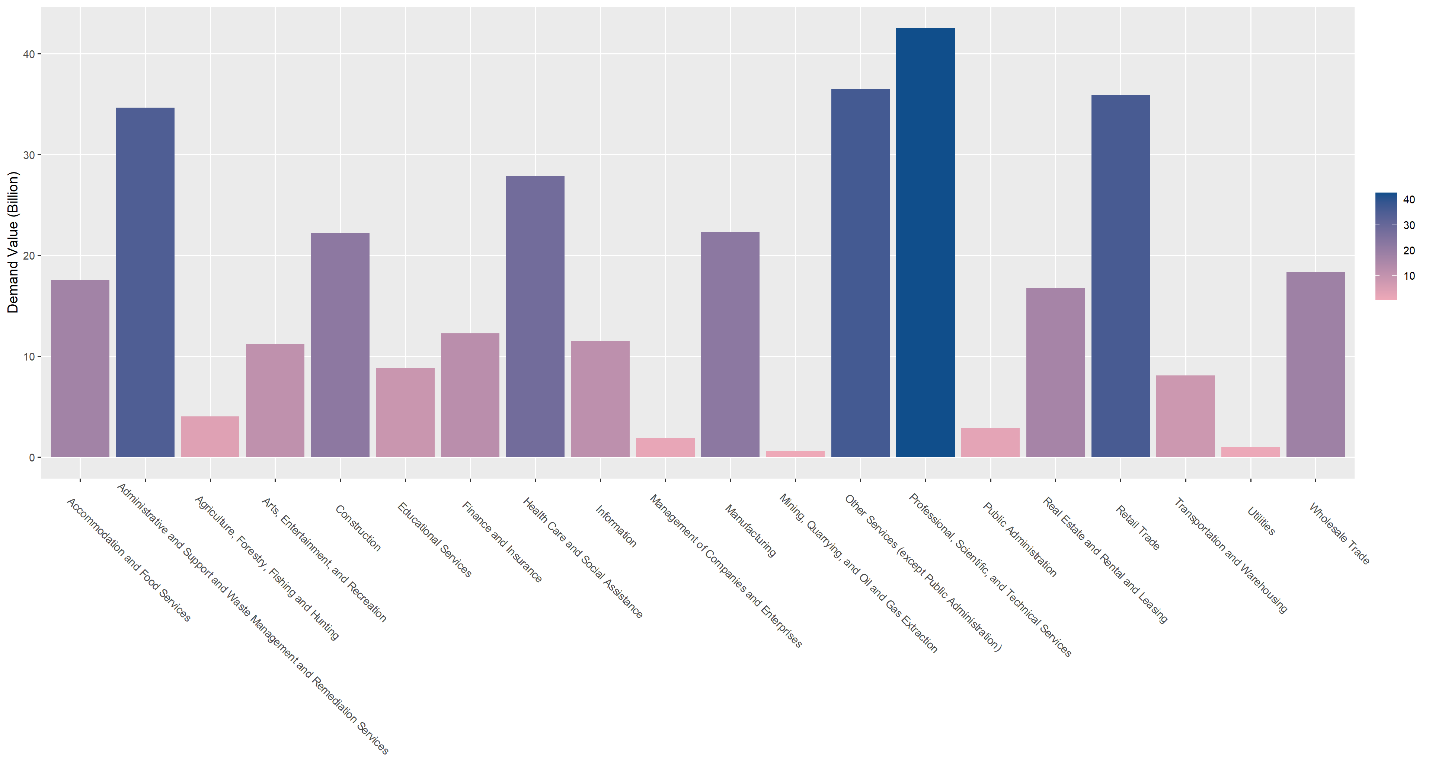
Примітка. На малюнку показано вартість праці з боку попиту в галузях із 2-значним кодом NAICS із використанням даних Built With. Для компаній (доменів), які пов’язані з кількома галузями, ми взяли середнє значення та розподілили його між галузями.
Малюнок 4 Розподіл створення цінності з відкритим кодом
Панель A. Сторона постачання
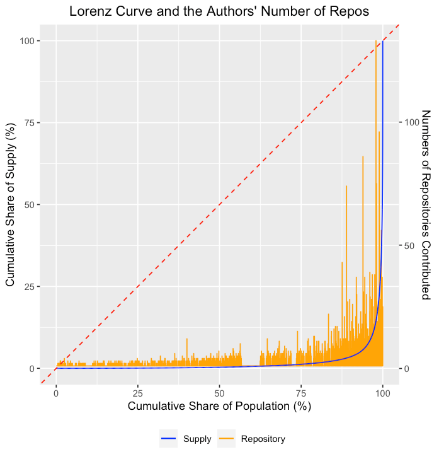
Панель B. Сторона попиту
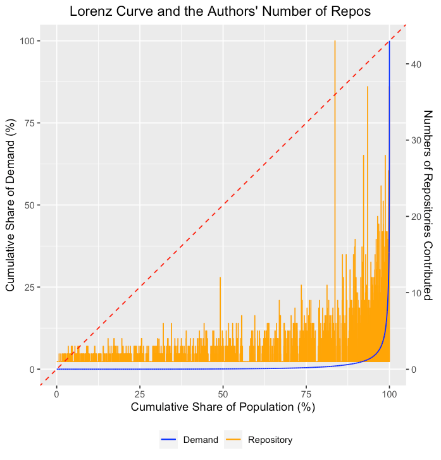
Примітка. Цифри показують криву Лоренца внеску вартості ринку праці на одного розробника (синім кольором), а також кількість сховищ, у які внесла частка програмістів (жовтим кольором). На панелі A відображається сторона постачання, а на панелі B – використання.
Таблиця 1 Описова статистика рядків коду та використання
| Sum | Mean | SD | Obs | |
|---|---|---|---|---|
| Панель А: Перепис | ||||
| Рядки коду – усі пакети | 261,653,728 | 142,203.1 | 887,937.2 | 1,840 |
| Рядки коду – 5 найкращих мов і Go | 189,673,184 | 113,712.9 | 702,832.1 | 1,668 |
| Використання – Усі пакети | 2,709,155 | 1472.4 | 2,167.9 | 1,840 |
| Використання – 5 найкращих мов і Go | 2,497,785 | 1497.5 | 2,228.8 | 1,668 |
| Панель B: BuiltWith | ||||
| Рядки коду – усі пакети | 82,504,613 | 111,342.3 | 613,488.1 | 741 |
| Рядки коду – 5 найкращих мов і Go | 58,664,935 | 79,925.0 | 354,415.0 | 734 |
| Використання – Усі пакети | 142,794.4 | 192.7 | 733.4 | 741 |
| Використання – 5 найкращих мов і Go | 142,751.2 | 194.5 | 736.6 | 734 |
Примітка. Статистика базується на рядках кодів різних репозиторіїв. Панель A (B) відображає загальну суму, середнє значення, стандартне відхилення та кількість спостережень для даних перепису (BuiltWith) у рядках коду та використання з використанням усіх пакетів із групи 1 (див. таблицю A1).
Таблиця 2 Вартість відкритого коду на ринку праці
| Пропозиція робочої сили | Попит на робочу силу | |
|---|---|---|
| Заробітна плата: низька | $1.22 Billion | $2.59 Trillion |
| Заробітна плата: глобальна | $4.15 Billion | $8.80 Trillion |
| Заробітна плата: висока | $6.22 Billion | $13.18 Trillion |
Примітка. Сценарій високої заробітної плати базується на середній заробітній платі в США, а сценарій низької заробітної плати – це середня заробітна плата програмістів в Індії у 2020 році. Загальна заробітна плата – це середня заробітна плата в країнах у таблиці A4, зважена відповідно до їхніх внесків у ВВК. Ці оцінки включають лише мови з програмного забезпечення, класифікованого у сегменті 1 (див. таблицю A1).
Онлайн-додаток
Таблиця A1 Мови в кожному сегменті
| Тип | Мова |
|---|---|
| Панель A: сегмент 1 – мови | |
| Мова розмітки | BIBTEX |
| Мова розмітки | COLDFUSION HTML |
| Мова розмітки | DOCBOOK XML |
| Мова розмітки | HAML |
| Мова розмітки | HTML |
| Мова розмітки | HXML |
| Мова розмітки | JAVAEE XML |
| Мова розмітки | MARKDOWN |
| Мова розмітки | MASON |
| Мова розмітки | MXML |
| Мова розмітки | RELAX-NG COMPACT |
| Мова розмітки | RHTML |
| Мова розмітки | TEX |
| Мова розмітки | XML |
| Мова розмітки | XQUERY |
| Мова розмітки | YAML |
| Мова програмування | ABNF |
| Мова програмування | ACTIONSCRIPT |
| Мова програмування | ADA |
| Мова програмування | APPLESCRIPT |
| Мова програмування | ARDUINO |
| Мова програмування | ASPECTJ |
| Мова програмування | ASPX-CS |
| Мова програмування | ASPX-VB |
| Мова програмування | AWK |
| Мова програмування | C |
| Мова програмування | C# |
| Мова програмування | CHARMCI |
| Мова програмування | CLOJURE |
| Мова програмування | COFFEESCRIPT |
| Мова програмування | COMMON LISP |
| Мова програмування | CSS |
| Мова програмування | CUDA |
| Мова програмування | CYTHON |
| Мова програмування | D |
| Мова програмування | DART |
| Мова програмування | DELPHI |
| Мова програмування | EASYTRIEVE |
| Мова програмування | EC |
| Мова програмування | ELIXIR |
| Мова програмування | ELM |
| Мова програмування | EMACSLISP |
| Мова програмування | ERLANG |
| Мова програмування | F# |
| Мова програмування | FISH |
| Мова програмування | FORTH |
| Мова програмування | FORTRAN |
| Мова програмування | FORTRANFIXED |
| Мова програмування | GAP |
| Мова програмування | GHERKIN |
| Мова програмування | GLSL |
| Мова програмування | GO |
| Мова програмування | GRAPHVIZ |
| Мова програмування | GROOVY |
| Мова програмування | HASKELL |
| Мова програмування | HAXE |
| Мова програмування | IDL |
| Мова програмування | JAVA |
| Мова програмування | JAVA SERVER PAGE |
| Мова програмування | JAVASCRIPT |
| Мова програмування | KOTLIN |
| Мова програмування | LESSCSS |
| Мова програмування | LIQUID |
| Мова програмування | LIVESCRIPT |
| Мова програмування | LLVM |
| Мова програмування | LOGOS |
| Мова програмування | LUA |
| Мова програмування | MATHEMATICA |
| Мова програмування | MINISCRIPT |
| Мова програмування | MODULA- 2 |
| Мова програмування | NASM |
| Мова програмування | NIX |
| Мова програмування | OBJECTIVE-C |
| Мова програмування | OBJECTIVE-J |
| Мова програмування | OCAML |
| Мова програмування | OPENEDGE ABL |
| Мова програмування | PAWN |
| Мова програмування | PERL |
| Мова програмування | PHP |
| Мова програмування | PL/PGSQL |
| Мова програмування | POSTSCRIPT |
| Мова програмування | POVRAY |
| Мова програмування | PROLOG |
| Мова програмування | PROPERTIES |
| Мова програмування | PUPPET |
| Мова програмування | PYTHON |
| Мова програмування | REASONML |
| Мова програмування | REBOL |
| Мова програмування | REDCODE |
| Мова програмування | REXX |
| Мова програмування | RUBY |
| Мова програмування | RUST |
| Мова програмування | S |
| Мова програмування | SASS |
| Мова програмування | SCALA |
| Мова програмування | SCILAB |
| Мова програмування | SCSS |
| Мова програмування | SLIM |
| Мова програмування | SMALLTALK |
| Мова програмування | SOLIDITY |
| Мова програмування | STANDARD ML |
| Мова програмування | SWIFT |
| Мова програмування | SWIG |
| Мова програмування | TADS 3 |
| Мова програмування | TCL |
| Мова програмування | THRIFT |
| Мова програмування | TRANSACT-SQL |
| Мова програмування | TREETOP |
| Мова програмування | TYPESCRIPT |
| Мова програмування | VB.NET |
| Мова програмування | VBSCRIPT |
| Мова програмування | VCL |
| Мова програмування | VIML |
| Мова програмування | WEB IDL |
| Панель B: Відро 2 – Допоміжні мови | |
| Асемблер/Компілятор/Інтерпретатор/Макропроцесори | GAS |
| Асемблер/Компілятор/Інтерпретатор/Макропроцесори | M4 |
| Асемблер/Компілятор/Інтерпретатор/Макропроцесори | RAGEL IN RUBY HOST |
| Конфігурація | CMAKE |
| Конфігурація | INI |
| Конфігурація | MAKEFILE |
| Конфігурація | NGINX Configuration FILE |
| Конфігурація | NSIS |
| Конфігурація | SQUIDCONF |
| Конфігурація | TERRAFORM |
| Конфігурація | TOML |
| Форматування | GROFF |
| IDE | NETBEANS PROJECT |
| Механізм шаблонів | CHEETAH |
| Механізм шаблонів | GENSHI |
| Механізм шаблонів | PUG |
| Механізм шаблонів | SMARTY |
| Механізм шаблонів | VELOCITY |
| Terminal/Batch | ANT |
| Terminal/Batch | APACHECONF |
| Terminal/Batch | BASH |
| Terminal/Batch | BATCHFILE |
| Terminal/Batch | MAVEN |
| Terminal/Batch | POWERSHELL |
| Terminal/Batch | RPMSPEC |
| Terminal/Batch | SINGULARITY |
| Terminal/Batch | TCSH |
| Перекладний | GETTEXT CATALOG |
| Панель C: сегмент 3 – дані | |
| Дані | BNF |
| Дані | DIFF |
| Дані | DTD |
| Дані | |
| Дані | JSON |
| Дані | PROTOCOL BUFFER |
| Дані | RESTRUCTUREDTEXT |
| Дані | TEXT ONLY |
| Дані | XSLT |
Таблиця A2 Включено 30 найкращих країн із глобальною заробітною платою
| Країна |
|---|
| United States |
| China |
| Germany |
| India |
| United Kingdom |
| Brazil |
| Russia |
| France |
| Canada |
| Japan |
| South Korea |
| Netherlands |
| Spain |
| Poland |
| Australia |
| Sweden |
| Ukraine |
| Italy |
| Switzerland |
| Indonesia |
| Taiwan |
| Colombia |
| Argentina |
| Mexico |
| Norway |
| Belgium |
| Denmark |
| Finland |
| Vietnam |
| Austria |
Примітка. 30 найкращих країн відсортовані в порядку зростання за часткою користувачів GitHub, і вони включають 88% активності GitHub з 2020 року.
Таблиця A3 Цінність ринку праці з відкритим кодом із використанням мов у сегментах 1 і 2
| Пропозиція робочої сили | Попит на робочу силу | |
|---|---|---|
| Заробітна плата: низька | $1.23 Billion | $2.60 Trillion |
| Заробітна плата: глобальна | $4.18 Billion | $8.84 Trillion |
| Заробітна плата: висока | $6.26 Billion | $13.24 Trillion |
Примітка. Сценарій високої заробітної плати базується на середній заробітній платі в США, а сценарій низької заробітної плати – це середня заробітна плата програмістів в Індії у 2020 році. Загальна заробітна плата – це середня заробітна плата в країнах, указаних у таблиці A 4. Оцінки включають лише мови з груп 1 і 2 (див. таблицю A1).
Таблиця A4 Вартість ринку праці з відкритим вихідним кодом із використанням мов у сегментах 1, 2 і 3
| Пропозиція робочої сили | Попит на робочу силу | |
|---|---|---|
| Заробітна плата: низька | $1.88 Billion | $3.52 Trillion |
| Заробітна плата: глобальна | $6.41 Billion | $11.96 Trillion |
| Заробітна плата: висока | $9.59 Billion | $17.91 Trillion |
Примітка. Сценарій високої заробітної плати базується на середній заробітній платі в США, а сценарій низької заробітної плати – це середня заробітна плата в Індії для програмістів у 2020 році. Загальна заробітна плата – це середня заробітна плата в країнах, указаних у таблиці A 4. Оцінки включають лише мови з груп 1, 2 , і 3 (див. таблицю A1).
Таблиця A 5 Кошик товарів – еквівалентне програмне забезпечення з відкритим кодом і пропрієтарне програмне забезпечення
| Програмне забезпечення з відкритим кодом | Закрите програмне забезпечення |
|---|---|
| Apache Http Server | Windows Server 2008 |
| Audacity | Adobe Audition |
| Blender | Autodesk Maya |
| Elasticsearch | Amazon Kendra |
| FileZilla | SmartFTP |
| FreeCAD | AutoCAD |
| GIMP | Adobe Photoshop |
| GNU Octave | MATLAB |
| GnuCash | QuickBooks |
| KeePass | 1Password |
| LibreOffice | Microsoft Office Suite |
| MariaDB server | Microsoft SQL Server |
| Metabase | Tableau |
| MySQL | Oracle MySQL |
| OpenVPN | ExpressVPN |
| PSPP | SPSS |
| Redis | Redis Enterprise |
| TensorFlow | TensorFlow Enterprise |
| VirtualBox | VMware Workstation |
| VLC Media Player | CyberLink PowerDVD |
Таблиця A6 Товарно-ринкова вартість відкритого коду з використанням мов у сегментах 1, 2 і 3
| Goods-Demand Bucket 1 | Goods-Demand Bucket 1-2 | Goods Demand, Bucket 1-3 | |
|---|---|---|---|
| Заробітна плата: низька | $177 Million | $179 Million | $242 Million |
| Заробітна плата: глобальна | $177 Million | $179 Million | $242 Million |
| Заробітна плата: висока | $177 Million | $179 Million | $242 Million |
Примітка. Сценарій високої заробітної плати базується на середній заробітній платі в США, а сценарій низької заробітної плати – це середня заробітна плата в Індії для програмістів у 2020 році. Загальна заробітна плата – це середня заробітна плата в країнах, указаних у таблиці A 4. Оцінки включають лише мови з груп 1, 2 , і 3 (див. таблицю A1).
Додаток A) Підхід до ринкової оцінки товарів
Як альтернативний метод оцінки замість використання відновної вартості праці ми використовуємо підхід відновної вартості товару. Ми визначаємо кілька пакетів ВВК, які мають подібні грошові альтернативи із закритим вихідним кодом, і розглядаємо витрати, якби всім комерційним користувачам безкоштовного ВВК довелося замінити це програмне забезпечення на грошову альтернативу (подібно до розрахунків Грінстайна та Нейгла (2014) та Мурчіано-Гороффа та ін. (2021) для веб-серверів). Потім ми можемо використати це альтернативне значення p у поєднанні зі значеннями q, наведеними вище, щоб оцінити вартість заміни товару ВВК. Цей метод ґрунтується на пропозиціях Нордгауза (2006, стор. 146), який каже, що «…ціна ринкових і неринкових товарів і послуг повинна розраховуватися на основі порівнянних ринкових товарів і послуг». Ми не очікуємо, що оцінки за двома методами будуть подібними. Навпаки, вартість цих двох методів суттєво різниться, оскільки останній товарно-ринковий підхід припускає фіксовану ціну, щоб продати товар кілька разів, і ця фіксована ціна зазвичай нижча за загальну вартість, оцінену на основі відтворення всіх пакетів з боку праці. Різниця між цими оцінками є, по суті, результатом того, що фірма втручається, щоб відтворити відсутні пакети ВВК і потім продає їх за грошову ціну, а не всім фірмам, які повинні відтворювати ці пакети з нуля самостійно. З підходом до ринку товарів уявний експеримент все ще полягає в тому, що ми живемо у світі, де ВВК не існує, але його потрібно відтворити за допомогою однієї фірми, яка потім стягує ціну за товар, який зараз є безкоштовним. Щоб оцінити ВВК за допомогою підходу ринку товарів, ми створили кошик еквівалентних запатентованих товарів-замінників, які оцінюються на відкритому ринку як заміна продукту ВВК. Ця методологія узгоджується з тією, що використовувалася в попередній літературі (Greenstein and Nagle, 2014; Murciano-Goroff et al., 2021), хоча в обох цих дослідженнях використовувався лише один товар, а не кошик, оскільки вони були зосереджені лише на одному типі ВВК (веб-сервери). Оскільки немає легкодоступної бази даних для власних еквівалентів ВВК, ми проводимо пошук на основі суб’єктивного сприйняття популярності ВВК, а потім шукаємо грошові, закриті замінники для них. Отриманий кошик із 20 пакетів ВВК із запатентованими замінниками є гарним уявленням про різноманітність ВВК. Програмне забезпечення варіюється від засобів масової інформації та програмного забезпечення для дизайну до програм статистичного аналізу, керування базами даних і програмного забезпечення веб-сервера.20
На основі нашого еквівалентного кошика пропрієтарних товарів-замінників ВВК ми потім отримуємо ціни для кожного еквівалента пропрієтарного програмного забезпечення та розраховуємо вартість пропозиції на ринку праці COCOMO для кожного продукту ВВК у кошику, який ми використовуємо як проксі – через відсутність коду з пропрієтарне програмне забезпечення – для цінності пропрієтарного програмного забезпечення COCOMO з боку пропозиції робочої сили (наприклад, вартість, яка знадобиться, щоб заплатити програмісту за написання цього пропрієтарного програмного забезпечення з нуля). Потім ми обчислюємо середню вартість кошика COCOMO на стороні пропозиції робочої сили $V_{S,Basket}$ і середню ціну кошика $P_{S,Basket}$.21 Оскільки , ми знаємо вартість пропозиції на ринку праці для всіх ВВК, $V_{S,Basket}$, ми можемо налаштувати наступне рівняння та отримати ціну ВВК, $P_S$ для ринку товарів для всіх ВВК за допомогою простого перетворення масштабування:
\[\frac{P_S}{V_{S}^{Labor}}=\frac{P_{S,Basket}}{V_{S,Basket}} P_S=\frac{V_{S}^{Labor}}{V_{S,Basket}}P_{S,Basket} (4)\]Це призводить до наступної вартості пропозиції на ринку товарів:
\[V_{S}^{Goods}=P_S * 1. (5)\]Тоді ми можемо отримати еквівалентні ринкові вартості товарів з боку попиту наступним чином:
\[V_{D}^{Goods} =𝑃_S∗Q. (6)\]З боку товарного ринку ми розглядаємо еквівалентну ціну, яку фірма стягувала б, якби виробляла всі наявні широко використовувані ВВК, а потім продавала їх як продукт клієнтам.
Таблиця A6, стовпець 3, показує, що вартість на стороні попиту коливається від 177 до 244 мільйонів доларів для різних сегментів, незалежно від країни походження, з якої наймають програмістів. Природно, ринкова вартість товару буде значно меншою, ніж вартість попиту на робочу силу, оскільки ця уявна фірма буде отримувати прибуток за порівняно низькою ціною, виробляючи програмне забезпечення один раз, а потім продаючи його багатьом клієнтам. Крім того, у той час як Greenstein and Nagle (2014), а також Murciano-Goroff et al. (2021) зосереджені лише на одному конкретному типі програмного забезпечення (веб-серверах), ми намагаємося розширити їхній підхід до багатьох товарів. Однак обмеження даних стають сильнішими обмеженнями в цьому контексті, що за своєю суттю ускладнює оцінку вартості за допомогою цього підходу, вимагаючи значно більше припущень. Замість чистого підходу ринку товарів, це потребує допомоги підходу ринку праці в плані масштабування для оцінки, що зрештою призводить до суттєвої недооцінки вартості ВВК. Крім того, стратегія ціноутворення аналогів пропрієтарного програмного забезпечення чутлива до ринкового попиту. Оскільки підхід ринку товарів поширюється на кілька товарів, сильним неявним припущенням є те, що ринковий попит на наше програмне забезпечення для кошика та наш зразок ВВК подібні, тому вони призводять до співмірних цін.
Альтернативний і ще більш спрощений розрахунок на задній частині ринку товарів, який не враховує рядки коду та не покладається на масштабування підходу ринку праці, полягав би просто в множенні ціни еталонного товару на використання. Ми можемо взяти мінімальну, середню та максимальну ціни кошика пропрієтарних товарів, зафіксованих у векторі базових цін p = (69,99, 1610,17, 5800), і просто помножити їх на використання комбінованої вибірки Census і BuiltWith (таблиця 1). . Виходячи з цих умовних припущень про власну ціну, вартість попиту на ринку товарів коливатиметься від 0,2 до 16,5 трильйонів доларів США (мінімальна ціна – максимальна ціна), а середня ціна дасть оцінку вартості в 4,5 трильйона доларів. Однак, незважаючи на те, що ця оцінка створює дещо більше розбіжностей, ніж підхід до ринку праці, вона за своєю суттю є хибною, оскільки просто припускає, що умовні ціни є ідентичними для кожного продукту з відкритим кодом на основі базової ціни. Крім того, ми вважаємо, що цей дуже простий зворотний бік конверта є порівнянням апельсина з яблуками, оскільки товари в нашому кошику є повністю функціональними, автономними пакетами програмного забезпечення, тоді як пакети в наборах даних Census і BuiltWith складаються з бібліотек програм, які зазвичай менші, ніж такі окремі пакети.
Враховуючи всі складнощі та припущення, які доводиться робити через брак даних для підходу товарного ринку, ми робимо більший акцент на підході вартості робочої сили, виділеному в основній частині, але ми включаємо цей метод тут для повноти.
-
точні методології збору та агрегування даних детально описано у звіті про перепис населення, автором якого є Нейгл та інші (2022). ↩
-
Ліцензії на використання ВВК дуже відрізняються, і хоча деякі ліцензії є дуже відкритими та дозволяють використовувати код у будь-який спосіб, зокрема в межах власного коду, який буде доступний для продажу за ненульовою ціною, інші ліцензії обмежити повторне використання, лише якщо отриманий код випущено під тією ж ліцензією ВВК (відома як копілефт). Детальне обговорення ліцензій ВВК можна знайти в Лернера та Тіроля (2005) та Алмейди та інших (2017). ↩
-
непряме використання ВВК фіксується аналізом залежностей і є необхідним для точного вимірювання повного спектру ВВК, на який покладається фірма. Наприклад, якщо власний код фірми викликає ВВК-пакет A, а пакет A, у свою чергу, викликає пакет B, тоді лише дивлячись на прямі виклики, ви пропустите, що пакет B був необхідним будівельним блоком для власного коду фірми. ↩
-
Перепис визначає пакет ВВК як «одиницю програмного забезпечення, яке може бути встановлено та кероване менеджером пакунків», а менеджер пакунків — як «програмне забезпечення, яке автоматизує процес інсталяції та іншого керування пакетами» (Nagle та інші, 2022). ↩
-
Пакети, які становлять решту 30% повних даних перепису в розподілі використання з довгим хвостом, не були представлені в остаточному звіті, тому їх не можна включити в наш аналіз. ↩
-
GitHub — це платформа для хостингу та співпраці, яку учасники можуть використовувати для координації розробки та розповсюдження проектів ВВК. GitHub, заснований у 2008 році, став найбільшим у світі центром розробки ВВК. У січні 2023 року GitHub мав понад 370 мільйонів сховищ і понад 100 мільйонів розробників. Окрім особистих користувачів, платформу GitHub активно використовує широкий спектр приватних компаній, у тому числі Microsoft (яка купила GitHub у 2018 році), Facebook, Google та численні інші малі та великі фірми. ↩
-
Ми спробували отримати доступ до всіх URL-адрес сховища, отриманих під час перевірки працездатності, щоб переконатися, що вони в робочому стані. Для тих, до яких ми не змогли отримати доступ на GitHub, ми вручну знайшли правильні URL-адреси. ↩
-
для перевірки надійності ми випадковим чином вибрали 50 збігів пакетів із сховищем, отриманих за допомогою методу пошуку Google, і перевірили їх вручну. Усі збіги було вручну підтверджено правильними, що забезпечує додаткову підтримку для автоматичного методу зіставлення. ↩
-
Оскільки назви пакета та менеджера пакунків відсутні, точна відповідність за допомогою libraries.io була неможливою. Назви технологій – це назви продуктів, призначені для клієнтів, і можуть бути менш технічними та точними, ніж назви пакетів для цілей внутрішньої розробки. Таким чином, використання назв технологій у пошуку libraries.io може спричинити значну неоднозначність. ↩
-
Коефіцієнт відповідності становить понад 96%, причому невідповідні сховища складають лише 0,15% від нашого розрахованого значення попиту на ВВК, яке обговорюється нижче. ↩
-
фільтрація базується на класифікації «підроблених користувачів» від GHTorrent, а також на будь-яких іменах користувачів, які містять слова «бот» або «робот», оточені спеціальними символами. Цей метод є більш консервативним, ніж інші методи виявлення ботів, як той, що використовується в GitHub Innovation Graph (https://innovationgraph.github.com/), який покладається на порогове значення частоти місячних комітів. ↩
-
Зауважте, що ми зосереджені на вартості відтворення коду ВВК, написаного людьми, а не роботами. Однак напряму видалити всі внески ВВК з облікових записів роботів тут неможливо, оскільки ми не можемо побачити точні рядки коду, написані обліковими записами роботів на GitHub. ↩
-
В альтернативній версії ми використовуємо поєднання підходу до ринку праці та товарів, який більше узгоджується з Greenstein and Nagle (2014) та Murciano-Goroff та ін. (2021). Однак застосування цього методу в наших умовах вимагає багатьох додаткових припущень через обмеження даних. Для простоти ми називаємо це підходом ринку товарів, для якого ми надаємо деталі та статистику, а також обмеження в Додатку A. ↩
-
ми використовуємо лише чисті рядки коду, за винятком рядків документації та порожніх рядків. Отже, ми недооцінюємо справжню цінність відтворення кожного пакета. ↩
-
Подібно до репрезентативної моделі агента (наприклад, див. Williamson 2006), можна подумати, що кожен пакет відтворюється окремими програмістами, які є ідентичними копіями один одного (і, отже, мають однаковий рівень кваліфікації, але не стають вищими ефективний через навчання). ↩
-
у Wachs et al. є 179 округів. (2022), але 30 найбільших країн складаються з понад 88% глобальних активних учасників, а кожна з решти має менше 0,6% частки. 30 найкращих країн наведено в таблиці A 2. ↩
-
ми обираємо референтні країни з високою та низькою заробітною платою на основі комбінації кількості активних розробників GitHub і середньорічної базової заробітної плати розробника програмного забезпечення. ↩
-
таблиці в додатку показують еквівалентні значення з таблиці 2, якщо включити сегменти мови програмного забезпечення 1 і 2 (таблиця A3) і всі три сегменти мови програмного забезпечення (таблиця A4). ↩
-
оскільки перепис містив конфіденційну інформацію про клієнтів, він не виявив галузей у всьому наборі даних, тому ми можемо показати значення для галузей лише за допомогою зовнішніх даних із BuiltWith. Ми зіставляємо веб-сайти BuiltWith з галузевою інформацією з наборів даних Orbis і Compustat. 94,6% веб-сайтів BuiltWith узгоджуються з галуззю завдяки цьому процесу. Для компаній (доменів), які пов’язані з кількома галузями, ми взяли середнє значення та розподілили його між галузями. ↩
-
Таблиця A5 показує кошик ВВК та їх власних еквівалентів, які ми використовували. Щоб створити цей кошик, ми шукали пропрієтарне програмне забезпечення, яке мало еквівалент ВВК, подібний за загальною функцією та набором функцій, і намагалися визначити пари програмного забезпечення, які в сукупності охоплювали широкий і репрезентативний набір типів ВВК, які існують. ↩
-
ми отримали середню ціну власного кошика товарного ринку, використовуючи 3 роки життя програмного забезпечення, тобто 1/(1-0,66), тому коефіцієнт амортизації становить 0,33. Це узгоджується з правилами Служби внутрішніх доходів США (IRS) щодо амортизації програмного забезпечення, де сказано: «Якщо ви можете амортизувати вартість комп’ютерного програмного забезпечення, використовуйте прямолінійний метод протягом терміну корисного використання 36 місяців». https://www.irs.gov/publications/p946#en_US_2022_publink1000107354. ↩